【AI入口不再追求“全民试玩”,大厂进入务实时代】
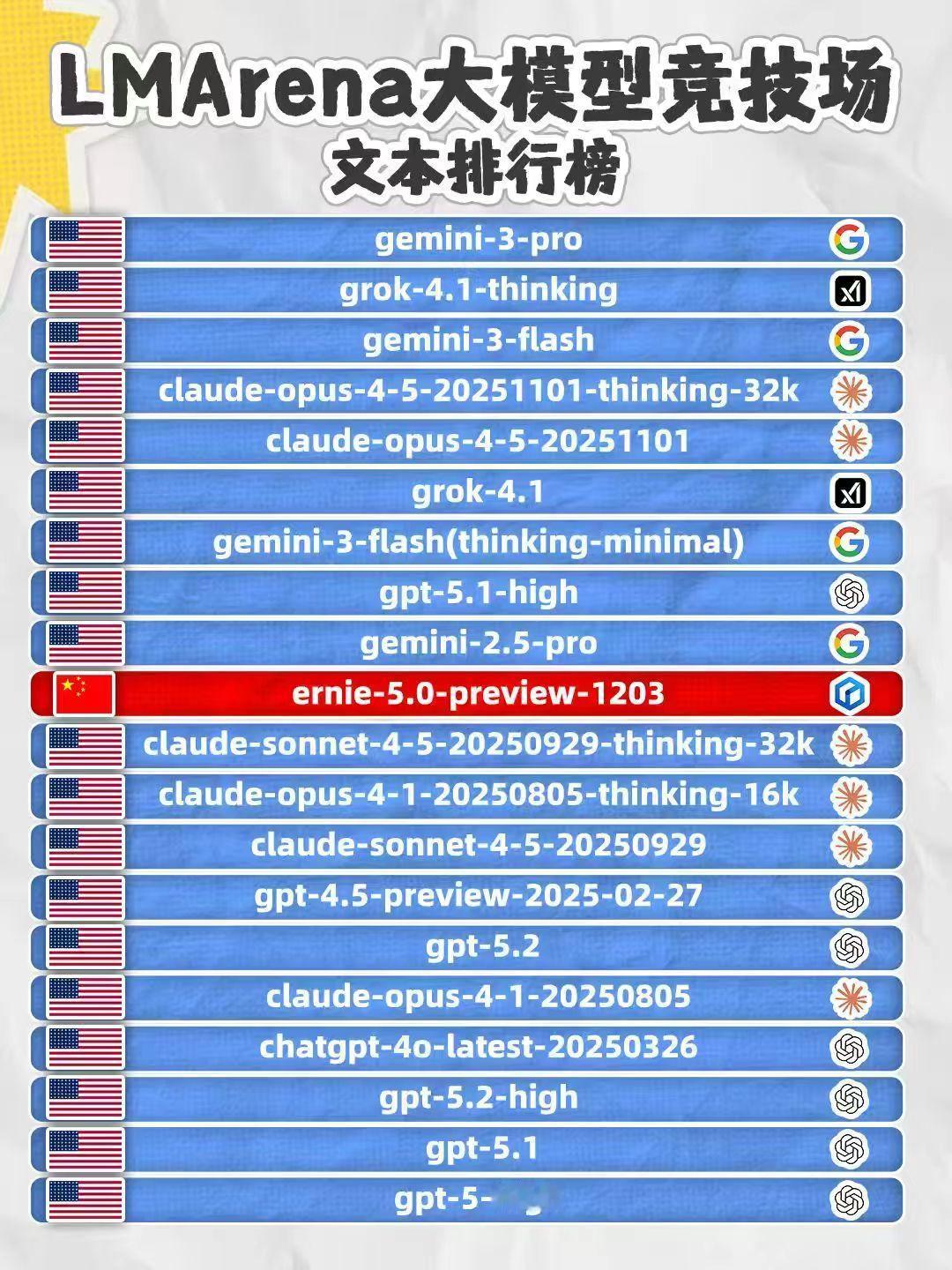
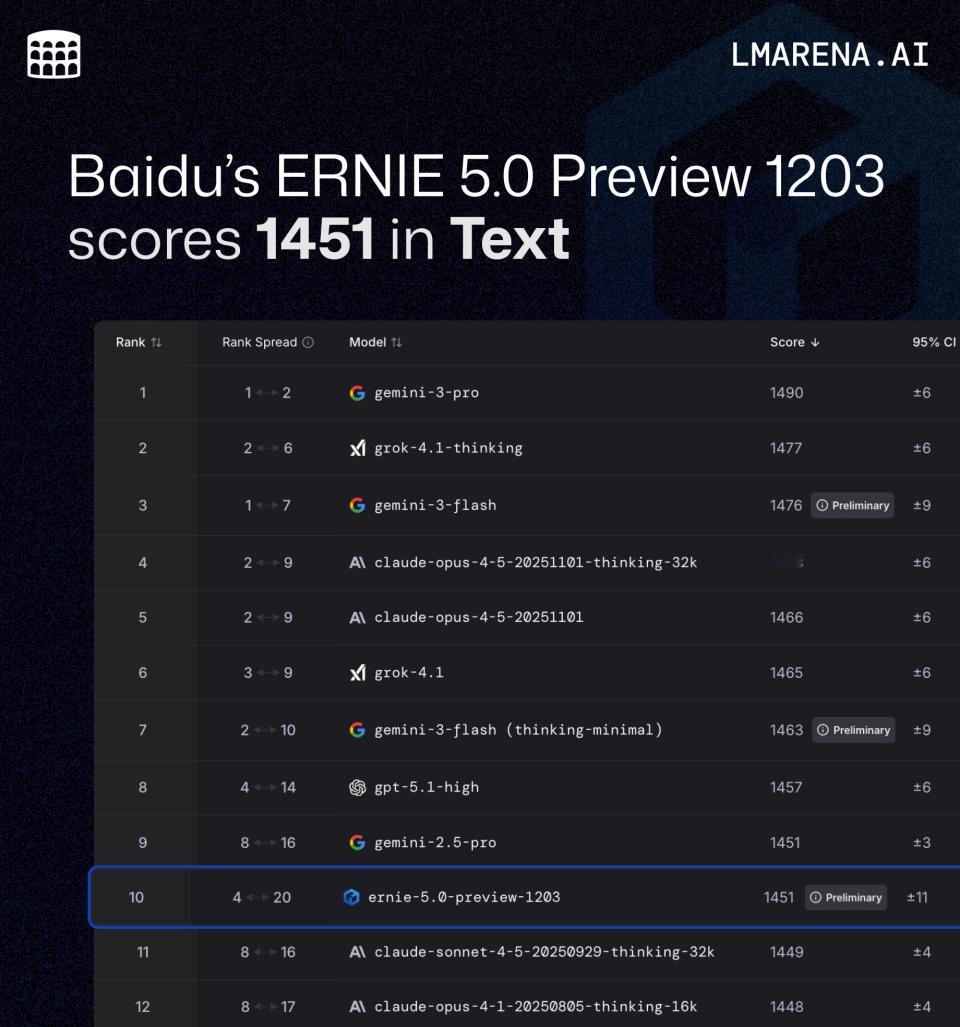
在最新公布的LMArena大模型文本能力榜单中,百度文心大模型5.0 Preview版本以1451分的表现摘得国内榜首,全球前10。其在创意写作、复杂指令理解等高阶任务上的评测结果尤为亮眼,综合表现已超越包括Claude-Opus-4-1、GPT-5.2在内的多款国际主流模型。
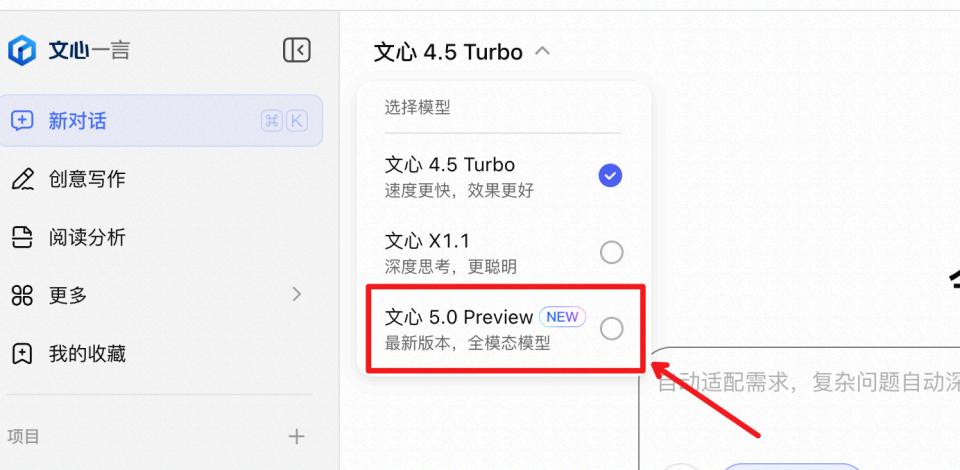
然而,与它在国际舞台上的高调表现形成鲜明对比的是,文心5.0 Preview在百度官方的产品入口中却显得相当“低调”。在文心一言网页版中,用户需要点击模型选择,才能在列表末尾找到“文心5.0 Preview(NEW)”这一选项,并未被置于显眼位置主动推广。
这一设计并非偶然。结合此前公开信息,文心5.0的总参数规模高达2.4万亿,是一个庞大的原生全模态模型。运行如此规模的模型,所需的算力成本是天文数字。行业普遍认为,百度此次没有将文心5.0 Preview推向最前台供全民“尝鲜”,是一种基于成本的克制策略。
这释放出一个清晰的行业信号:AI竞赛的下半场,正在从“拼曝光”转向“拼攻坚”。在模型刚进入大众视野的阶段,争夺用户注意力、培养使用习惯是关键。而一旦进入真正的生产应用阶段,稳定性、响应速度和长期运营成本就成为更核心的竞争力。将有限的、昂贵的算力资源,优先保障给真正有复杂需求的商业场景和关键任务,而非被海量的简单闲聊或尝鲜请求所消耗,成为一种更务实的选择。
当前,国内拥有百亿、千亿参数规模的模型已不鲜见。行业的痛点已从“有没有大模型”,转变为“如何用好大模型”。高质量的指令数据、能与业务深度结合的真实任务、以及最终可衡量的投资回报率(ROI),成为了新的稀缺资源。
文心5.0 Preview此次在LMArena上展现的,恰恰是在“创意写作”、“复杂提示理解”这类贴近真实、高价值场景下的能力突破。这或许正是其战略聚焦的体现:不追求在简单对话上“炫技”,而是锚定那些能体现模型深度思考与创造力的核心赛道,提前在专业评测中验证能力,为后续企业级应用的稳定表现铺路。
纵观LMArena榜单,另一个细节更值得玩味:在总分排名前20的模型中,文心5.0Preview是唯一一个非美国模型。它不是在“国产模型”的单独分类里自成一格,而是直接与GPT、Claude、Gemini等国际巨头被放在同一维度下比较、评分。
这标志着一种叙事的转变。过去我们常讨论“国产模型能否追上国际先进水平”,而现在,部分领先的国产模型已经开始在国际公认的“擂台”上,与最顶尖的选手同台竞技,并在某些单项上取得优势。从“追赶者”到“竞争者”,角色正在悄然转换。
尽管目前仍是Preview版本,但结合其近期频繁的版本迭代与榜单亮相,业内普遍猜测文心 5.0 正式版将于 1 月上线。当它真正全面开放时,所带来的或许不是又一轮全民狂欢,而是一场针对产业智能化需求的、更加沉稳有力的赋能。AI的狂热渐退,务实时代已然来临。
百度 文心一言 文心 文心大模型ai AI大模型 科技 AI技术