【OpenMythos:从第一性原理,还原 Claude Mythos 的 “思考” 本质】
这不仅是一个代码库,更是一场关于大模型“思考”本质的深度实验。Kye Gomez 推出的 OpenMythos,试图从第一性原理出发,还原那个让业界惊叹的 Claude Mythos 背后可能的运行逻辑。
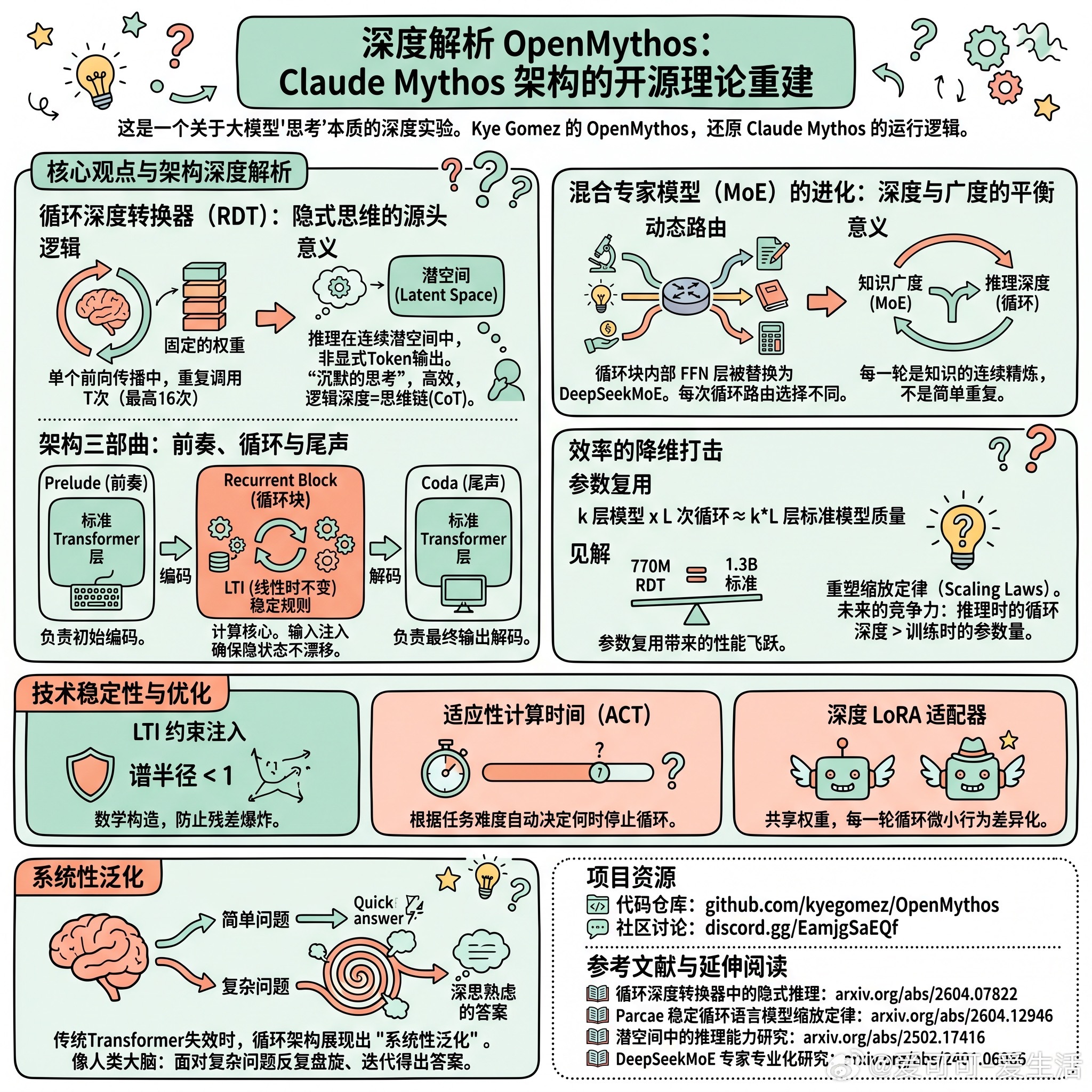
核心观点与架构深度解析
1. 循环深度Transformer (RDT):隐式思维的源头OpenMythos 的核心假设是:Mythos 并非无限堆叠层数,而是一个循环深度Transformer。- 逻辑:它在单个前向传播中,将一组固定的权重重复调用 T 次(最高可达 16 次)。- 这意味着推理发生在连续的潜空间(Latent Space)中,而不是通过显式的 Token 输出。这是一种“沉默的思考”,在逻辑深度上等同于思维链(CoT),但效率更高。
2. 混合专家模型 (MoE) 的进化:深度与广度的平衡在循环块内部,FFN 层被替换为类似 DeepSeekMoE 的精细化 MoE 设计。- 动态路由:最关键的创新在于,路由器的选择在每一次循环中都是不同的。- 这意味着每一轮循环并不是简单的重复,而是针对不同领域知识的连续精炼。MoE 提供了知识的广度,而循环提供了推理的深度。
3. 架构三部曲:前奏、循环与尾声- Prelude(前奏):标准 Transformer 层,负责初始编码。- Recurrent Block(循环块):计算核心,通过 LTI(线性时不变)稳定规则进行输入注入,确保隐状态在多次循环中不漂移。- Coda(尾声):标准 Transformer 层,负责最终输出解码。
4. 效率的降维打击- 参数复用:一个 k 层的模型运行 L 次循环,可以达到 k 乘以 L 层标准模型的质量。- 性能飞跃:在 770M 参数规模下,RDT 的表现足以匹配 1.3B 的标准模型。- 见解:这重塑了缩放定律(Scaling Laws)的讨论——未来的竞争力可能不再是训练时的参数量,而是推理时的循环深度。
技术稳定性与优化
为了解决循环模型常见的训练不稳定问题,OpenMythos 引入了三项关键机制:- LTI 约束注入:通过数学构造确保谱半径小于 1,从根本上防止残差爆炸。- 适应性计算时间 (ACT):允许模型根据任务难度自动决定何时停止循环。- 深度 LoRA 适配器:在保持权重共享的同时,让每一轮循环拥有微小的行为差异化。
传统的 Transformer 在处理从未见过的逻辑组合时往往会失效,而循环架构展现出了“系统性泛化”的能力。它更像人类的大脑:面对简单问题快速反应,面对复杂问题则在脑中反复盘旋、多次迭代,最终得出一个深思熟虑的答案。
OpenMythos 证明了:推理深度是推理时间计算量(Inference-time Compute)的函数,而不仅仅是存储参数的堆砌。
项目资源
代码仓库:github.com/kyegomez/OpenMythos社区讨论:discord.gg/EamjgSaEQf
参考文献与延伸阅读
- 循环深度Transformer中的隐式推理:arxiv.org/abs/2604.07822- Parcae 稳定循环语言模型缩放定律:arxiv.org/abs/2604.12946- 潜空间中的推理能力研究:arxiv.org/abs/2502.17416- DeepSeekMoE 专家专业化研究:arxiv.org/abs/2401.06066