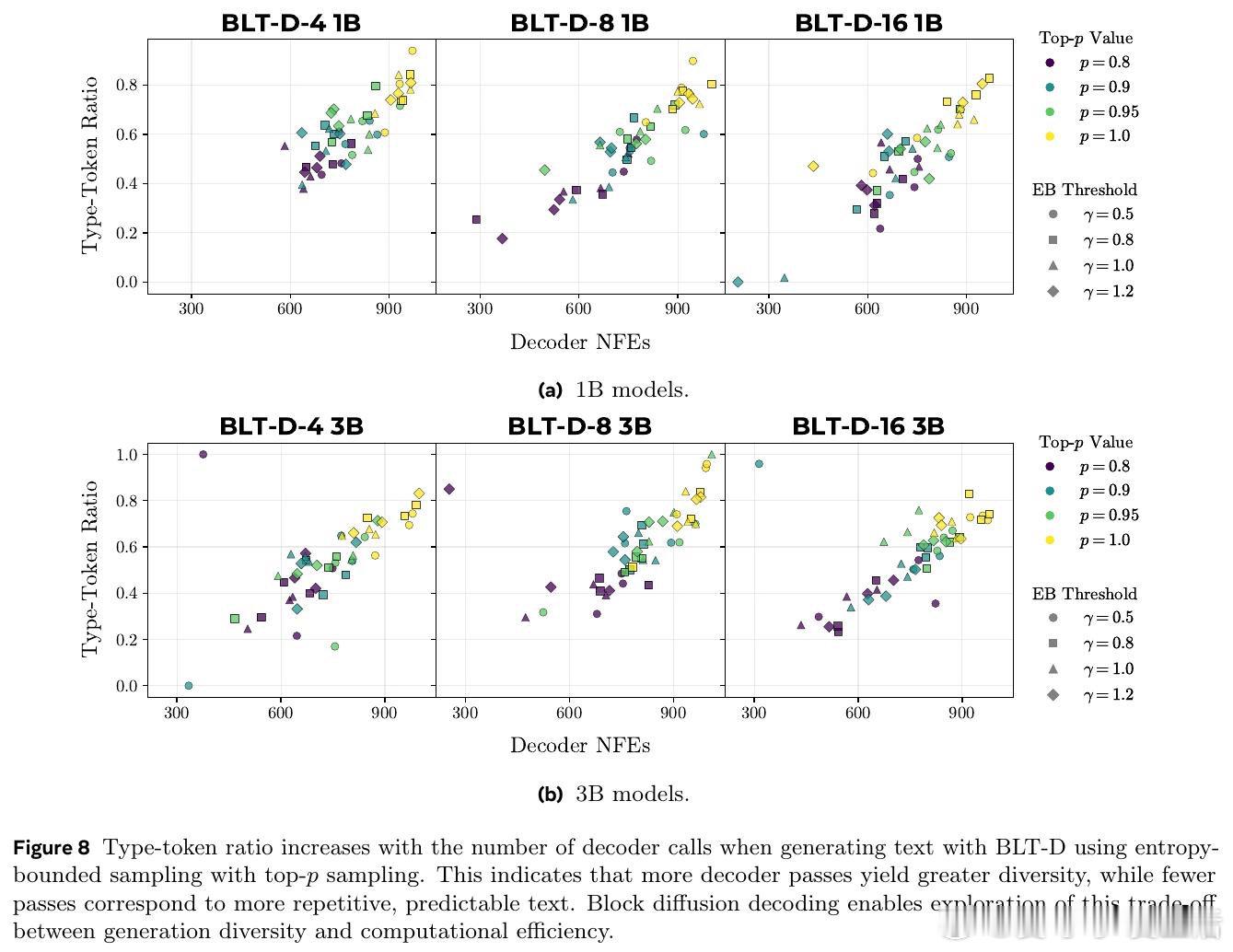
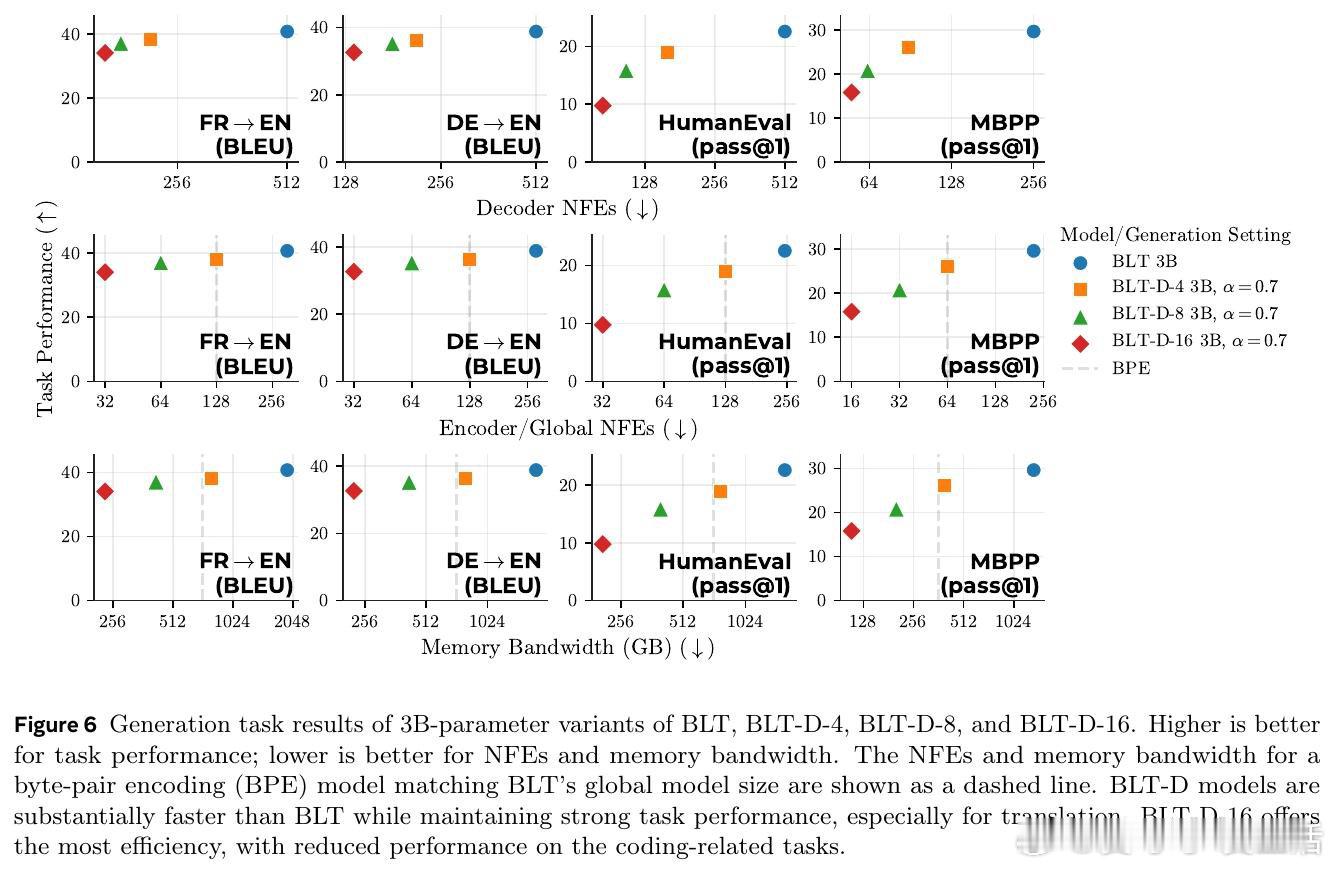
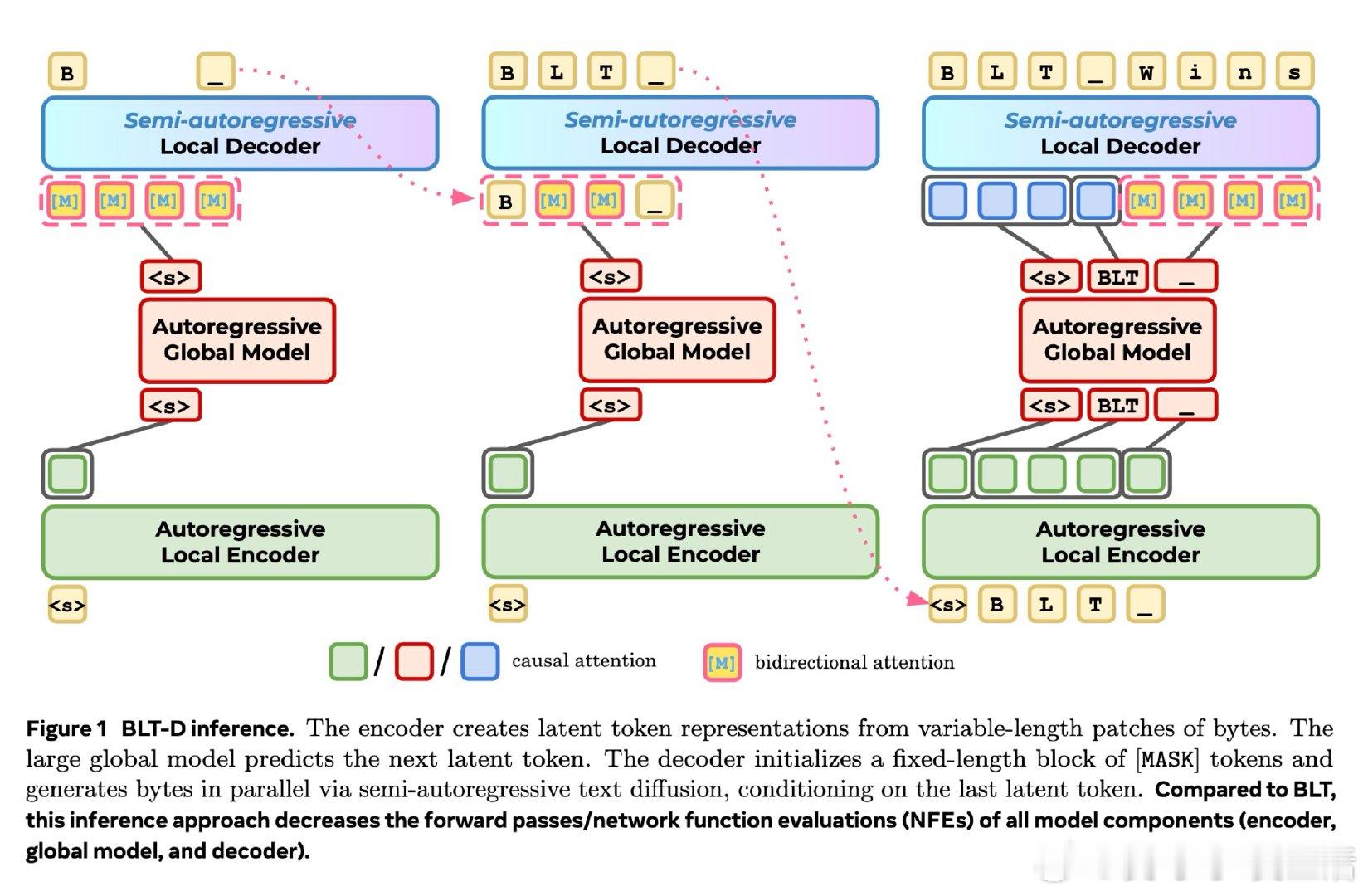
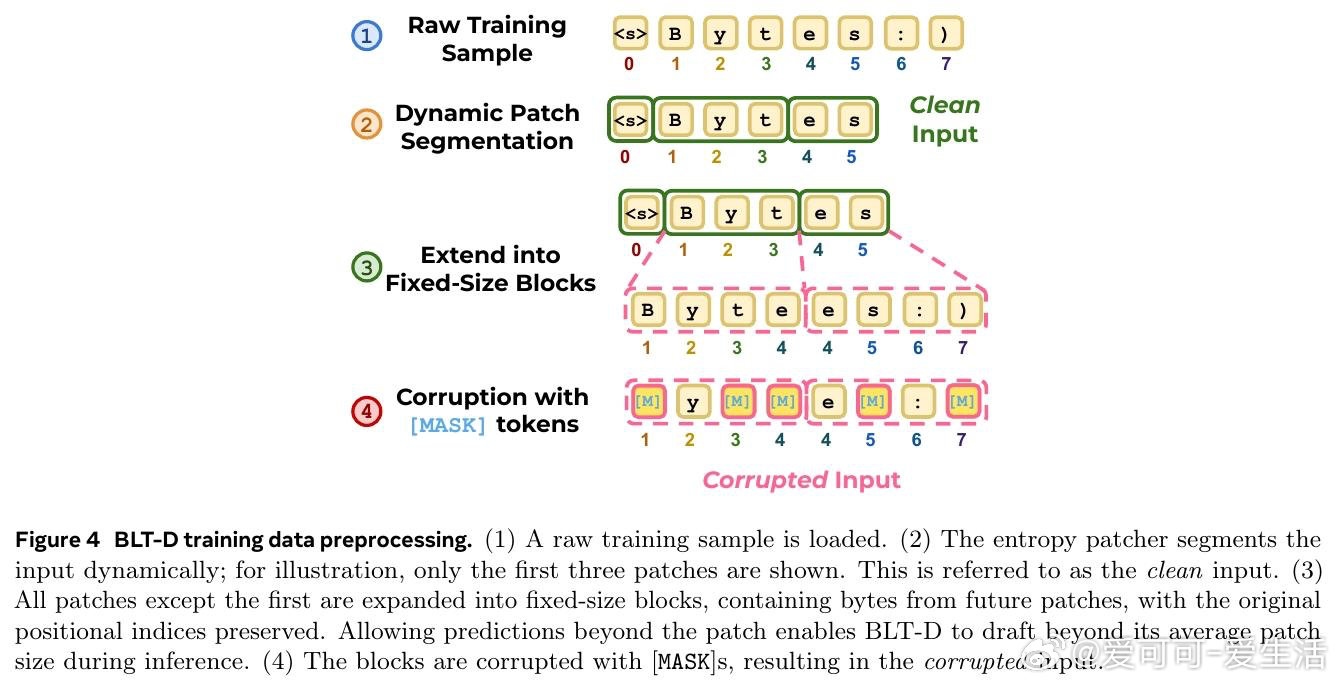
[CL]《Fast Byte Latent Transformer》J Kallini, A Pagnoni, T Limisiewicz, G Ghosh, L Zettlemoyer, C Potts, X Han… [FAIR at Meta] (2026)
在字节级语言模型中,免 tokenizer 与快速生成难以兼得。过去 BLT 虽用动态 patch 降低计算,但仍逐字节解码,本质原因是未来字节不能并行生成。
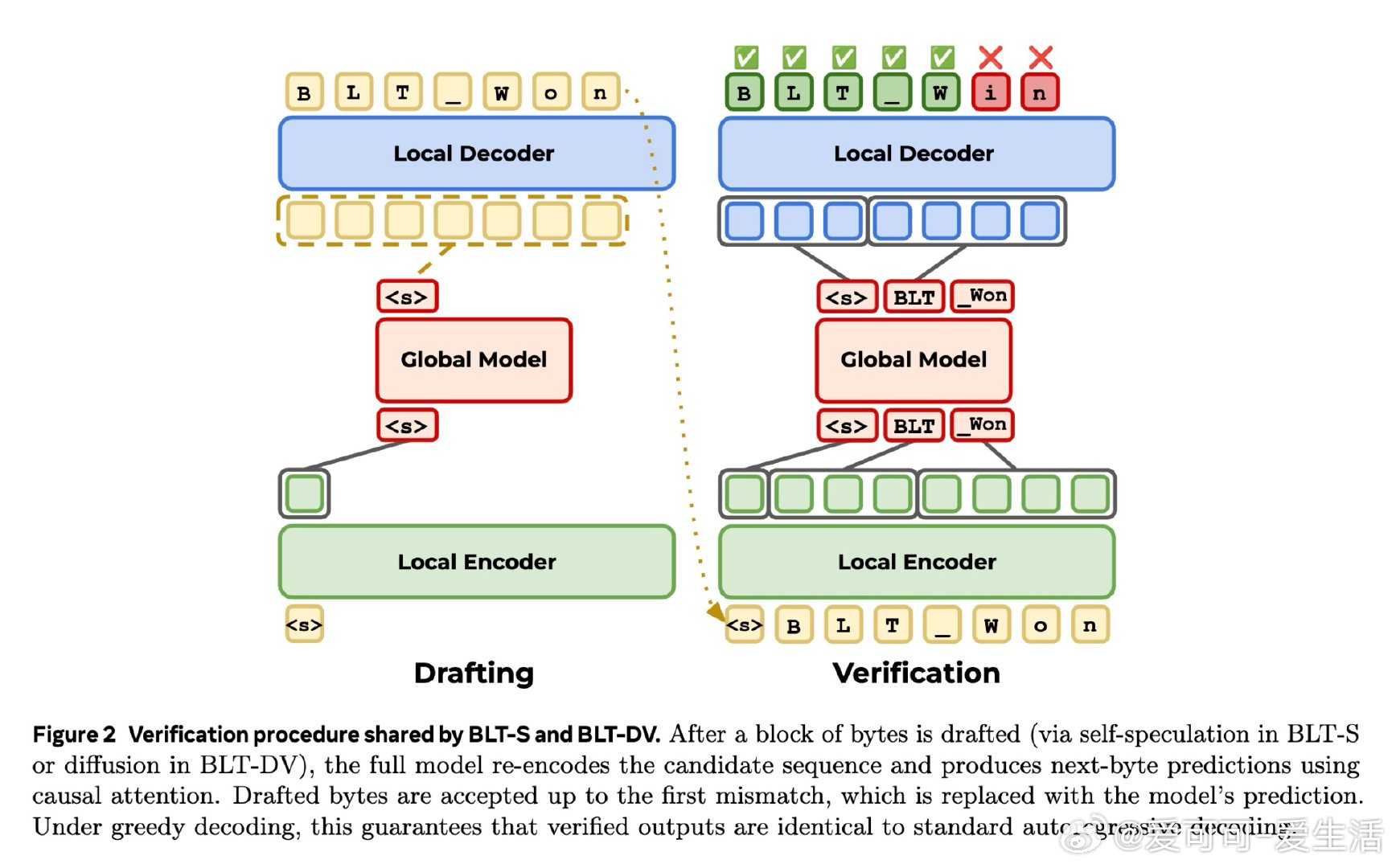
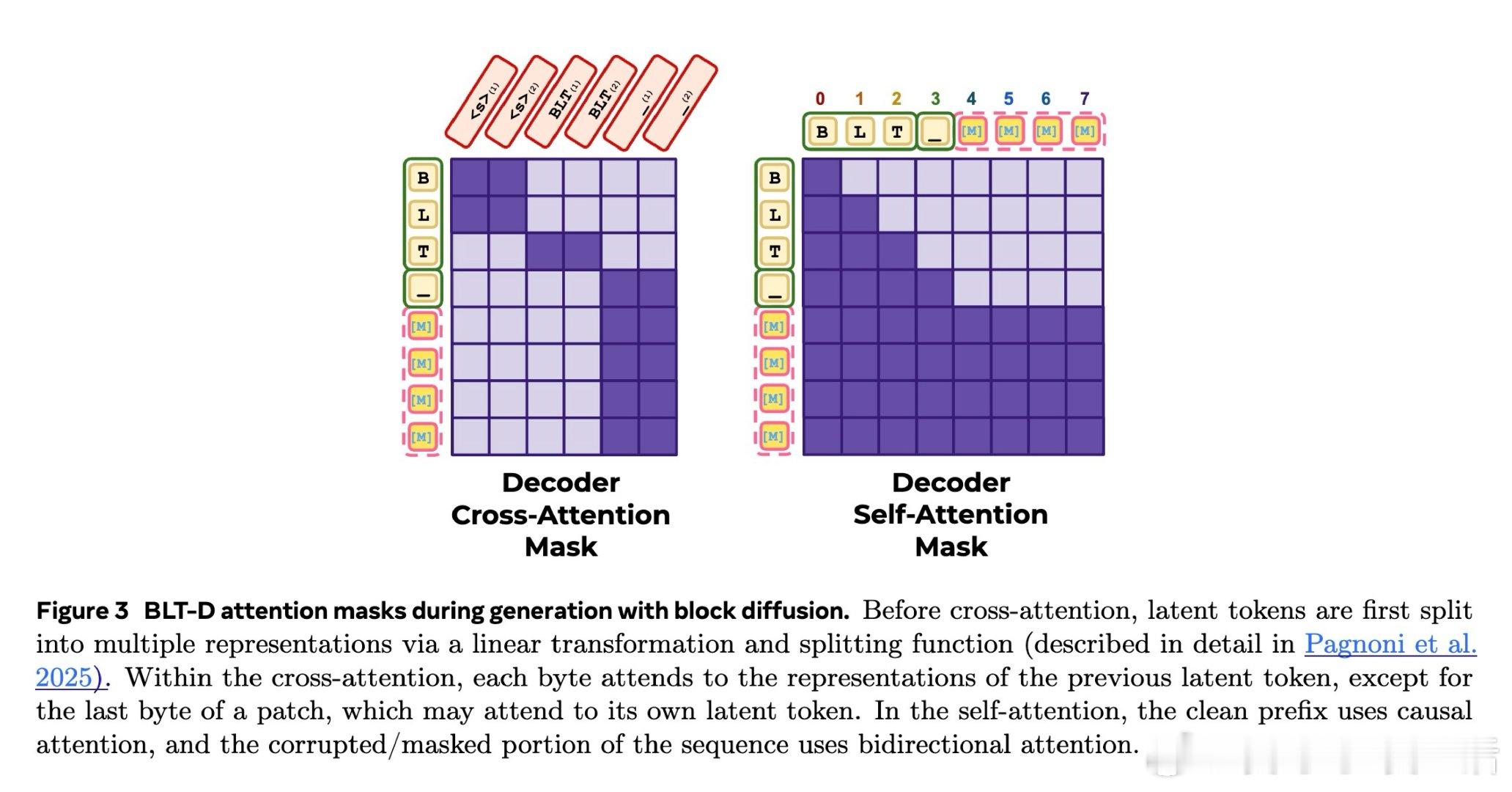
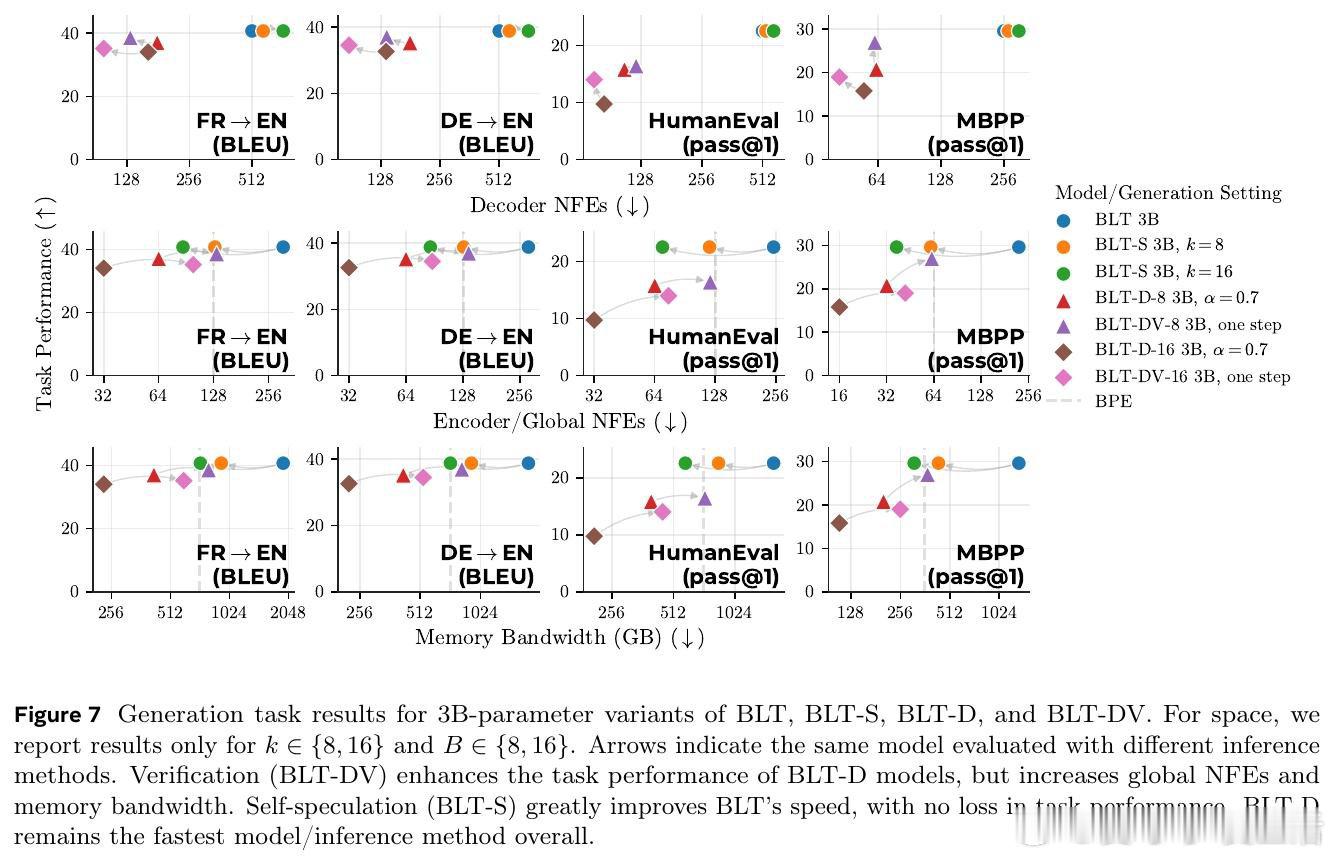
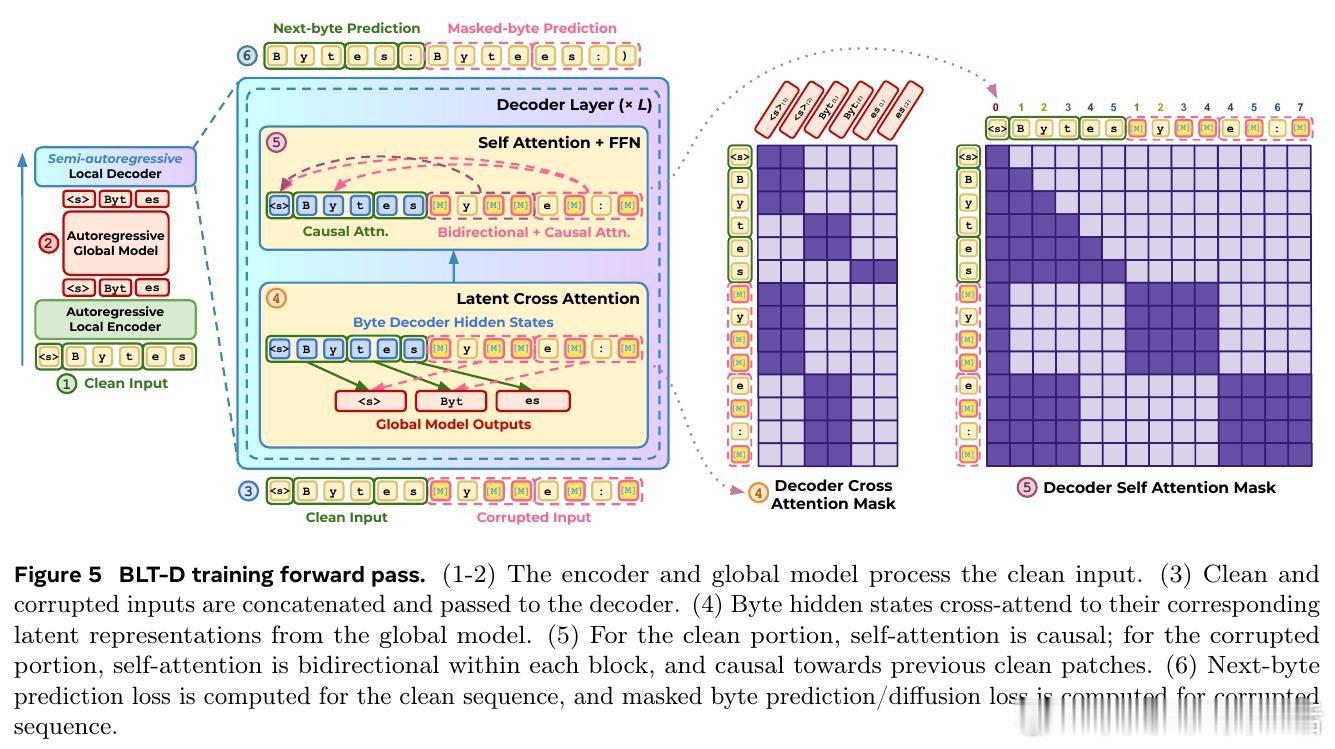
本文的核心洞见是:把 BLT 解码重新看作块级补全。由此,扩散目标让 decoder 一次草拟多字节,再用自推测或自回归校验在速度与质量间调节。
这项工作真正留下的遗产是让字节模型接近实用推理。它打开的新门是 tokenizer-free 的并行生成,但尚未跨过的门槛是真实系统延迟仍只用 NFE 与带宽估计。
arxiv.org/abs/2605.08044 机器学习 人工智能 论文 AI创造营