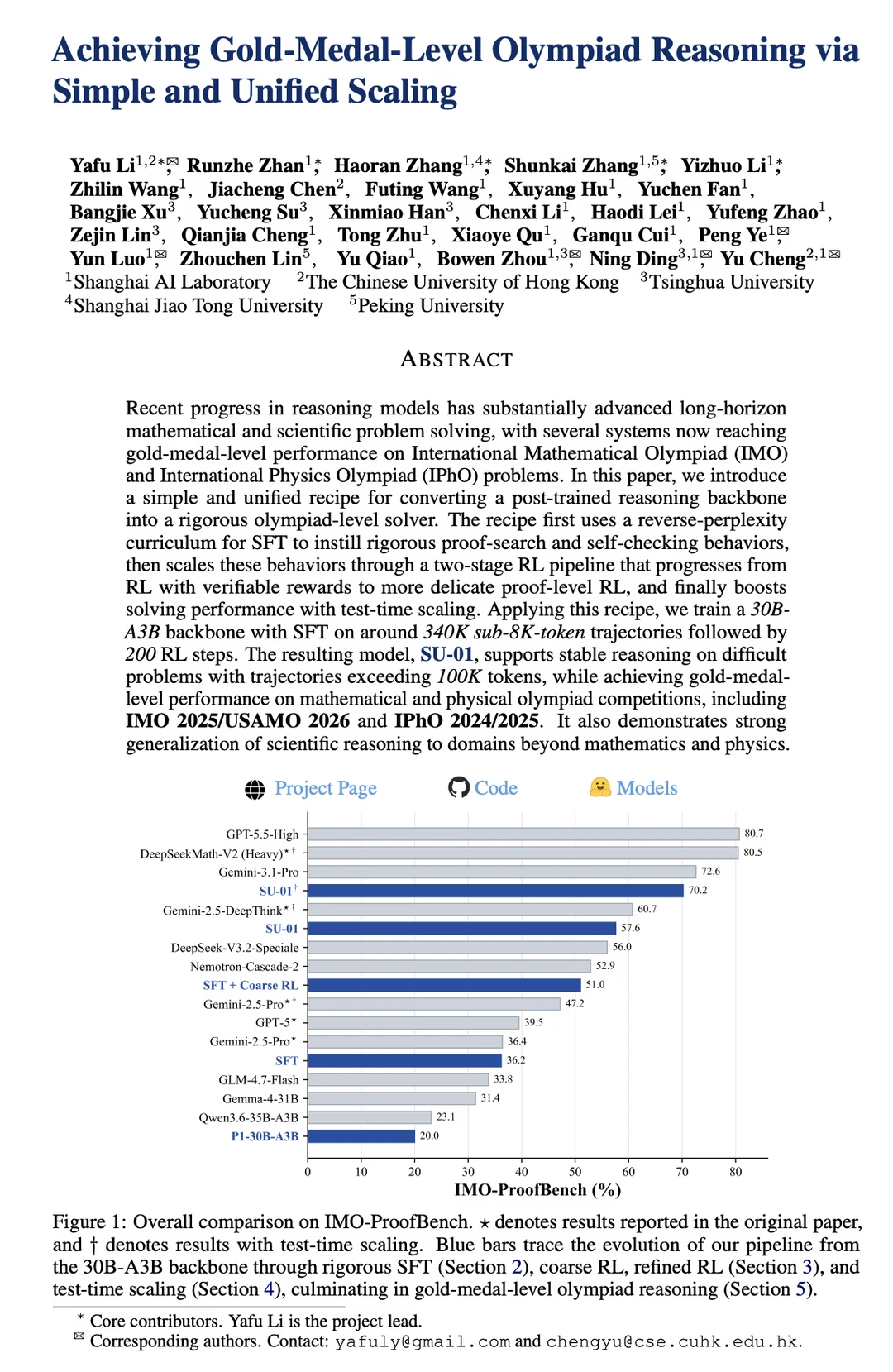
上海人工智能实验室联合香港中文大学、清华等团队推出的 SU-01,用一个简单且统一的配方,把一个普通的后训练推理模型,成功升级为高水平奥赛求解器。
过去,能达到金牌表现的系统要么方案保密,要么流程极其复杂,缺少一条清晰可复现的路径。而 SU-01 真正把这件事「说清楚、讲明白了」。
他们的三步配方非常简洁:
第一步:Reverse-Perplexity SFT(反困惑度课程微调)
不按常规随机顺序训练,而是根据模型对样本的初始困惑度从高到低排序。先喂最难预测、最不熟悉的严谨证明轨迹,再逐步过渡到熟悉样本。
这样既让模型学会了系统性的证明搜索、自查自纠习惯,又最大程度保留了原有 backbone 的能力。
第二步:两阶段强化学习(RL)
第一阶段(Coarse RL):用答案正确性作为可验证奖励,重点提升模型的搜索能力和难题直接求解率。
第二阶段(Refined RL):切换到证明质量的生成式奖励,加入自我精炼和经验回放,专门打磨证明的严谨性和完整度。
第三步:Test-Time Scaling(测试时缩放)
推理时允许模型「多想一会儿」。通过「求解 → 验证找 bug → 修正」的循环迭代,让模型生成超过 10 万 token 的长思考轨迹,把算力重点用在最难的问题上。
整个过程只用了约 34 万条 SFT 轨迹 + 200 步 RL,效率很高,而且不绑定特定模型,容易迁移。
它证明了不需要海量数据和极其复杂的系统,只需「行为重塑 + 可扩展反馈 + 测试时计算」的闭环,就能让中小规模模型在高难度长时序证明任务上达到专家水平。为开源社区提供了一条清晰、可落地的从「通用推理模型」到「严谨奥赛求解器」的路径,也为更广泛的科学推理研究打开了新思路。
模型和代码据已经公开,推荐感兴趣的朋友去读原文或尝试复现。如果你觉得对你有用的话 ~ 欢迎点赞收藏并分享给你的朋友们~