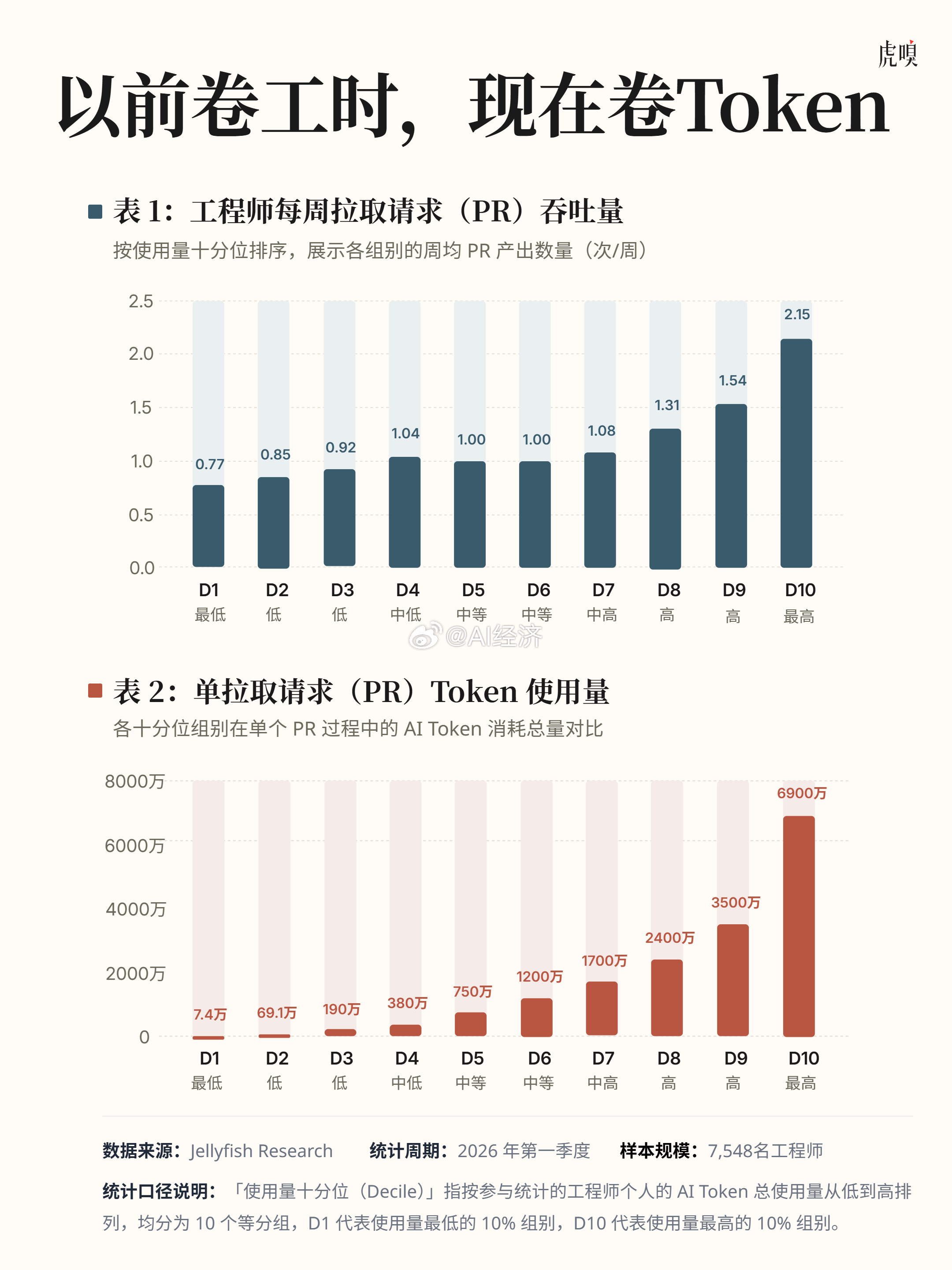
AI时代,新的“摸鱼方式”出现了这两年,微软、亚马逊、Meta这些硅谷大厂,原本指望靠AI把人力成本干下来,可现实是,员工调用AI越来越频繁,一个任务越扯越长,最后企业买算力的钱,涨得比省下的人工还快。 逼得一些公司开始收紧第三方AI工具权限,要求员工优先用内部平替,先把成本控制住。 表面上看,这不科学。这两年大模型调用费明明一直在降,按理说AI应该越来越便宜。但公司的真实情况是:模型降价了,使用量却通胀了。员工开始把越来越多的工作,直接丢给Agent这类工具处理。这种全自动的工具比传统的问答对话框耗能多得多,成本很容易就滚雪球了。 更荒唐的是,很多公司还没摸索出成熟的AI工作流,却先把“有没有用AI”写进了KPI。亚马逊就有员工承认,自己会故意把一些无关紧要的工作丢给AI做,就是为了把内部的“活跃度数据”刷上去。 公司原本想考核员工有没有用AI提高产出,可一旦“使用率”成了硬性指标,事情就变味了。为了显得自己足够积极,打工人只能把AI调用量拉满。到最后,大家不卷工作结果,开始卷数据。 硅谷智能公司Jellyfish发现,Token消耗最高的那批“卷王”,耗费了普通人10倍的AI算力,最终写出的代码却只多了2倍。而代码分析机构GitClear的报告更扎心:AI写出的低质量代码正在大量堆积,导致代码的翻修和重构率在近年大幅飙升。 管理学大师彼得·德鲁克曾说:“没有什么比高效率地做一件根本不该做的事,更无用的了。”说到底,AI不会自动带来效率。如果公司只会鼓励“多用”,却不会管理“怎么用、用在哪、值不值”,最后得到的往往不是智能化,而是更昂贵的形式主义。 以前打工人摸鱼,是假装很忙;以后打工人摸鱼,可能是假装自己特别会用AI。芒果一口气宣了89部大剧