
今天凌晨,Anthropic 在官方博客发布了一篇长文,标题名为《When AI Builds Itself》(当 AI 开始建造自己)。目前浏览量已接近 700 万。
文章由公司联合创始人 Jack Clark 与内部研究机构 The Anthropic Institute 负责人 Marina Favaro 共同署名。核心观点可以用一句话概括:AI 正加速参与到自身的开发进程当中。如果这个趋势走到极端,AI 将能够在没有人类介入的情况下,自主设计、测试并训练出更强大的下一代 AI。基于这一判断,Anthropic 呼吁全球主要 AI 实验室考虑暂停 AI 开发,或者至少建立一套可以互相核查的减速机制。

(来源:X)
这番表态之所以格外引人关注,不仅因为内容,也因为说这番话的是 Anthropic。
就在文章发布前几天,Anthropic 刚刚完成最新一轮融资,估值达到 9,650 亿美元,正式超过 OpenAI。同一周,公司向美国证券交易委员会秘密递交了 S-1 注册声明草案,启动 IPO 筹备流程。Anthropic 的年化营收正快速攀升,从 2025 年底的约 90 亿美元增长到当前的接近 470 亿美元,预计本月底将突破 500 亿美元。在公司即将冲击公开市场、商业势能最强的时候,却发出“请考虑减速”的信号,很难让人不疑惑其动机。
不过在讨论动机之前,不能否认的是,这篇文章确实拿出了实打实的内部数据。而这些数据之所以重要,是因为它们指向了一个越来越明确的趋势:AI 研发自动化。
AI 研发自动化正在成为行业共识
Anthropic 的文章主要围绕一个概念展开——“递归自我改进”(Recursive Self-Improvement,简称 RSI),指的是 AI 系统自主完成设计、测试、训练下一代 AI 的完整流程,人类不再扮演关键角色。这个概念并不新鲜,但过去一年里,它正从理论走向现实。几乎所有头部 AI 公司都在往这个方向投入资源。
以 OpenAI 为例,这家公司已经将“AI 参与 AI 研发”列入重点关注事项。其安全团队专门设立了“Recursive Self-Improvement Preparedness(递归自我改进准备)”相关岗位,用于研究当 AI 能够显著加速自身研发时可能带来的能力跃迁与风险。OpenAI 此前公开透露,其内部目标是在 2026 年前后打造达到“研究实习生”水平的 AI 系统,并在 2028 年实现能够独立承担研究任务的自动化 AI 研究员。
Google DeepMind 走的是一条更偏算法发现的路线。它的 AlphaEvolve 项目让 AI 自主提出算法方案、运行实验、筛选结果,再将优秀方案反馈回系统继续迭代。这套系统已经被用于数据中心调度优化和 AI 训练效率提升等实际场景,据报道还找到了 56 年来首个对 Strassen 矩阵乘法算法的改进。从某种意义上说,这也是 DeepMind 对“奇点”判断的重要依据之一:当 AI 开始参与甚至推动新的科学发现和算法创新时,技术进步将进入加速循环。
头部公司之外,越来越多创业公司也开始围绕“自动化 AI 研发”布局。例如近期获得大额融资的 Recursive Superintelligence,以及将“构建擅长 AI 研发的系统”写入公司使命的 Mirendil,都是这一趋势的代表。虽然技术路径各不相同,但它们瞄准的是同一个目标:让 AI 从研发工具变成研发过程的参与者,并最终承担越来越多的研发工作。

图 | Recursive Superintelligence 创始成员(来源:X)
正是在这个背景下,Anthropic 发布了这篇长文。它的立场是:RSI 还没有发生,也不一定会发生,但它到来的速度“可能比大多数机构准备好的时间更快”。
AI 已经在多大程度上接管了 AI 研发?
在文章中,它用三组此前未公开的内部数据支撑了这个判断。
第一组数据是关于 AI 的代码能力。截至 2026 年 5 月,Anthropic 合并到生产代码库中的代码有超过 80% 由 Claude 编写。2025 年 2 月 Claude Code 上线之前,这个比例还是个位数。与之对应,2026 年第二季度工程师人均每天合并的代码量达到 2024 年的 8 倍。文章专门补充说明:代码行数衡量的是数量而非质量,8 倍很可能高估了真实的生产力提升。但趋势是明晰的:工程师的角色正在从“写代码”转向“指引方向和审查结果”。

(来源:Anthropic)
而且 Claude 写的代码质量还在快速提升。Anthropic 内部跟踪了工程师在 Claude Code 工作过程中需要纠正或中途接管的频率,这个频率在过去一年持续下降。到 2026 年 5 月,Claude 处理最高难度开放式任务的成功率达到 76%,六个月内上升了 50 个百分点。
第二组数据涉及了 AI 的科研能力。Anthropic 有一个内部基准测试:给 Claude 一段训练小型 AI 模型的 CPU 代码,要求它在不改变正确性的前提下尽可能提速。2025 年 5 月,Claude Opus4 的平均加速比约为 3 倍;到 2026 年 4 月,Claude Mythos Preview 达到了约 52 倍。
作为参照,一名熟练的人类研究员通常需要四到八小时才能达到约 4 倍加速。Anthropic 提醒,绝对倍数受起始代码优化空间的影响,不应直接解读为真实世界的训练加速,但在同一测试条件下,一年内从 3 倍到 52 倍的变化,这个结果值得重视。
第三组数据来自工程实践。2026 年 4 月,Claude 自主修复了超过 800 个 API 错误,将该类错误的发生率降低了约 1,000 倍。负责的工程师估计,同样的工作让人来做大概需要四年。因为修复别人写的 Bug 实在是一个漫长而痛苦的过程,人类也很难同时记下那么多不熟悉的代码上下文,可这类任务恰恰是 AI 的优势所在。
文章还公布了一个颇有意思的实验。2026 年 4 月,研究人员将多个 Claude 智能体交给一个 AI 安全领域的开放问题:弱模型能否可靠地监督强模型?智能体自行提出假设、设计实验、运行测试,在并行智能体之间共享发现并迭代。两位人类研究员花了一周时间,弥补了该任务性能上下限之间约 23% 的差距;Claude 智能体累计运行 800 小时后,弥补了 97% 的差距。
更值得注意的是,AI 提升的不只是执行能力,连“下一步该做什么”的判断能力也在同步增强。Anthropic 内部的一项回溯评测显示,当研究人员在项目推进过程中走入错误方向时,Claude 越来越能够提出更优的替代方案。最新模型 Claude Mythos Preview 给出的研究路径,有 64% 的概率被评审认为优于人类研究者当时的实际选择。这意味着 AI 开始不仅能帮助研究者完成工作,也正在越来越多地参与研究方向本身的选择。
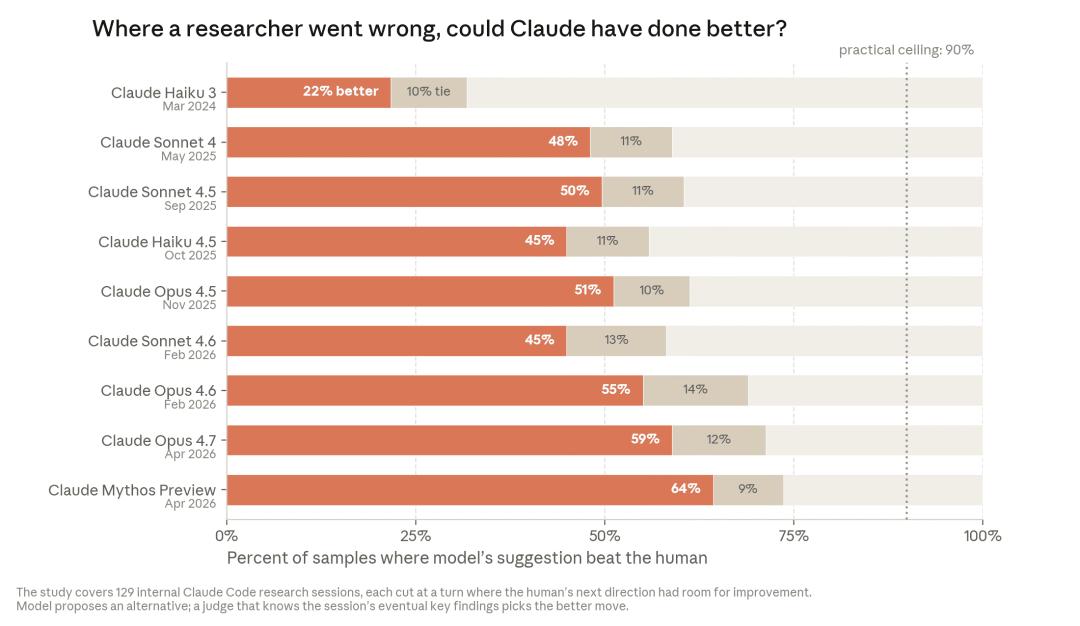
(来源:Anthropic)
这些数据拼在一起,指向的是同一个大的趋势:AI 正在接管越来越多原本由研究人员亲自完成的工作。写代码、调试系统、运行实验、分析结果,这些过去占据大量时间的研发环节,正越来越多地由 AI 完成。人类的角色则逐渐从执行者转向监督者和决策者。
正因为如此,此前 Jack Clark 对递归自我改进的时间表判断相当激进。他在 2026 年 5 月的 newsletter 中估计,到 2028 年底出现完全自动化 AI 研发的概率约为 60%,到 2027 年底约为 30%。
如果 Clark 的判断成立,那么问题很快就会从“RSI 是否可能出现”变成“当它真的出现时怎么办”。因此,Anthropic 这篇文章真正想讨论的,其实不只是技术,还有技术发展过快之后的治理问题。
在文章中,Anthropic 提出了三种可能的未来:第一种是 AI 能力增长逐渐放缓,但现有能力已经足以广泛扩散;第二种是 AI 继续带来复合型效率提升,人类仍负责设定研究方向,但越来越多执行环节被自动化;第三种,也是最激进的一种,是 AI 系统真正具备完整的递归自我改进能力,开始自主构建下一代模型。Anthropic 最担心的是后两种情形,因为它们留给社会、政府和安全研究的准备时间都非常有限。
在文章最后,Anthropic 将问题的答案落到“减速”与“核查”上。它认为,如果能有效放慢前沿 AI 开发,让社会制度和对齐研究跟上技术进展,这很可能是一件好事。但单方面暂停意义有限,因为它只会改变谁是领先者,并不会让整个行业获得真正的讨论时间。真正有用的暂停,必须是多国、多家前沿实验室在相同条件下共同减速,并且能够彼此验证对方确实停了下来。
呼吁暂停的人,未必能停下
但回到开头的问题,作为一家势头正猛且即将上市的公司,Anthropic 呼吁停止 AI 开发的动机真的如此纯粹吗?
公开讨论前沿 AI 的潜在风险,确实是 Anthropic 的一贯作风。从成立至今,这家公司确实已经多次发布关于模型能力、安全治理和监管框架的研究与政策文件。只不过这一次,它讨论的对象从 AGI 进一步推进到了 RSI。
联创 Clark 在接受 Axios 采访时解释说:“我们一直发现,最好的做法是让大家理解这个概念,让人们了解即将发生什么。”他说文章背后的核心判断是,“与一些流行观点相反,AI 进步在未来几年将会加速,保持不变或放缓的可能性不大。”他还表示,Anthropic 希望立法者在真正频繁听到“递归自我改进”之前,就提前了解这个话题。
但这个解释显然无法消除所有质疑。
风险投资人 David Sacks,他同时也是特朗普的重要科技顾问。近期就在播客中公开批评 Anthropic。他认为,所谓全球核查机制听上去是在防范风险,但实际效果很可能是抬高行业门槛。按照他的逻辑,能够满足审查、合规和安全要求的,往往是 Anthropic、OpenAI、Google 等拥有雄厚资金和算力的大公司;而开源模型天然分散在全球各地运行,很难被统一监管。最终的结果,可能不是让 AI 更安全,而是让少数头部公司获得更大的优势。
此前,类似的质疑也出现在产品层面。例如在推出网络安全模型 Mythos 时,Anthropic 对模型访问权限进行了严格限制,理由是其能力过于强大,可能被用于攻击关键基础设施。支持者认为这是负责任的安全措施,但批评者则质疑,公司是否在有意强化“危险但先进”的形象,以突出自身技术领先地位。
沃顿商学院教授 Ethan Mollick 对这些矛盾的态度给出了自己的解释。他认为,Anthropic 内部实际上同时存在多种力量。一部分人像其他科技公司一样负责商业化、市场和法律事务;一部分研究人员专注于打造更强大的下一代模型;还有一部分人则真正关心 AI 长期可能带来的社会影响与风险。在 Mollick 看来,这些群体并不总是立场一致。Anthropic 之所以经常呈现出一边加速推进模型能力、一边公开讨论潜在风险的矛盾形象,很大程度上正是这种内部张力的结果。
但还有一个更现实的问题:即便所有人都相信风险存在,真的有人能停下来吗?当所有参与者都处于激烈竞争的环境里,“谁在别人暂停时继续跑,谁就可能继承领先地位”。
文章最后提出的方案是,Anthropic 将在未来数月组织政策制定者、研究人员以及其他 AI 公司参与讨论,探索构建一套可核查的暂停机制。按照设想,多个国家的多个前沿实验室需要在相同条件下同时停止开发,并且每一方都能验证其他参与者确实停了下来。如果这样的机制存在,Anthropic 表示自己“预计会减速或暂停”。
“如果”二字,看似轻松,却承载了巨大的重量。历史上,无论是核军控还是其他国际技术治理体系,都花费了数十年时间才建立起核查机制、执行能力和跨国信任。而 AI 的扩散速度远快于这些先例,“如果”真正要让整个行业一起踩下刹车,可能比实现 RSI 还要困难。
参考链接:
1.https://www.anthropic.com/institute/recursive-self-improvement
2.https://the-decoder.com/anthropic-co-founder-maps-out-how-recursive-ai-improvement-could-outpace-the-humans-meant-to-supervise-it/
3.https://www.axios.com/2026/06/04/anthropic-warns-ai-build-successors
4.https://www.wsj.com/tech/ai/anthropic-urges-global-pause-in-ai-development-flags-self-improvement-risk-99cefb73?mod=tech_lead_story
运营/排版:何晨龙
注:封面/首图由 AI 辅助生成