别再只盯着哪个模型更强了 真正决定结果的是有没有第二个模型专门拆台
很多人还在争谁更聪明,谁更会写,谁更会编程。这个讨论已经开始过时了。
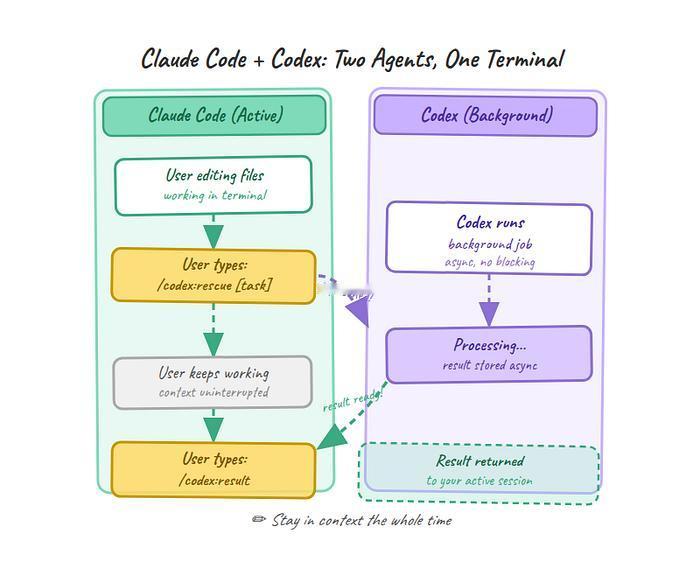
真正影响结果的,往往不是你选了哪一个模型,而是你有没有把第二个模型放进流程里,让它专门负责反对、审查、挑错、补洞。一个负责生成,一个负责怀疑,这才是最近最值得重视的变化。
原因很简单。模型最容易出问题的地方,从来不是表面上的流畅度,而是那些看起来不显眼、实际最容易埋雷的细节。比如代码能跑,但异常没有接住。接口返回正常,但关键字段缺失。研究报告写得像模像样,但证据链并不完整。单模型最容易把这种问题包装得很像正确答案,第二个模型的价值,就是把这种包装拆开。
现在这套思路,已经从个人工作流走向企业产品了。常见的协作方式大致分成两种。第一种是顺序式,先由一个模型起草,再由另一个模型在后台复核,最后用户只看到一份已经整理过的答案。第二种是并行式,两个模型同时独立完成同一任务,再由第三个模型做综合,哪里一致,哪里分歧,都会被摊开。
这两种方式没有谁天然更高级,关键看你把结果拿去做什么。只是想提升日常效率,顺序式很舒服,因为页面干净,交互顺滑,结论也更省心。可一旦任务进入金融、法务、审计、风控这些高责任场景,顺滑未必是第一优先级。透明度才是。
问题就出在这里。后台复核看起来很美,但如果最后只给一份答案,却没有清楚记录到底哪个模型生成了哪一段判断,哪个版本参与了哪一次推理,后面就会很麻烦。今天能用,不代表明天能解释。模型静默升级了怎么办,关键结论是起草模型给出的,还是复核模型改写后的,能不能追溯到具体版本,这些都直接决定它适不适合进入严肃业务。
所以我现在的判断很直接。双模型协作一定会越来越常见,而且确实能提升质量。但下一阶段真正拉开差距的,不再是谁的回答更像人,而是谁能把生成、审查、修订、归因这条链条交代清楚。答案写得漂亮,只能说明它会输出。过程说得明白,才说明它能承担责任。