英文题目:Learning realistic lip motions for humanoid face robots
中文题目: 为人形面部机器人学习逼真的嘴唇运动
作者:Yuhang Hu, Jiong Lin, Judah Allen Goldfeder, Philippe M. Wyder, Yifeng Cao, Steven Tian, Yunzhe Wang, Jingran Wang, Mengmeng Wang, Jie Zeng, Cameron Mehlman, Yingke Wang, Delin Zeng, Boyuan Chen, Hod Lipson(通讯)
作者单位: 哥伦比亚大学
期刊:Science Robotics(IF 27.5 中科院一区,JCR一区)
发表时间:2026年1月14日
链接:
https://www.science.org/doi/10.1126/scirobotics.adx3017
引文格式:Hu Y, Lin J, Goldfeder J A, et al. Learning realistic lip motions for humanoid face robots[J]. Science Robotics, 2026, 11(110): eadx3017.
01 全文速览
机器人能开口说话,但你能忍受它“口型对不上”吗?研究显示,人们在对话中会把近一半的视觉注意力集中在说话者的嘴唇上。一旦音画不同步,那种“不对劲”的感觉会立刻触发恐怖谷效应,让信任感直线下降。
哥伦比亚大学Hod Lipson团队给出了一个系统级解决方案。他们设计了一款10自由度的软硅胶仿人脸,让嘴唇能做出更接近人类的精细动作(比如发“w”时的噘嘴、发“b”时的闭唇)。但更关键的是,他们放弃传统的“预设动作库”思路,转而采用自监督学习:先让机器人通过“运动咿呀学语”(motor babbling)自主采集2万组唇形-电机指令数据,再用变分自编码器(VAE)把真实图像和合成图像映射到统一的隐空间,最后用一个面部动作Transformer(FAT) 从语音音频直接推断出平滑的电机轨迹。
实验结果显示:在11种语言(包括英语、法语、日语、俄语、阿拉伯语等)上,这个框架的唇动同步精度显著优于幅度映射、最近邻等基线方法,且用户偏好度达到62.5%(P<0.0001)。更重要的是,它不需要为每种语言重新训练——训练数据主要是英语,但能直接泛化到其他语系。
核心亮点:
✅ 10自由度唇部机构:独立控制上唇、下唇、嘴角、下颌,能还原24个辅音和16个元音的典型唇形
✅ 自监督学习:无需人工标注,机器人通过随机运动自主采集数据,结合Wav2Lip合成视频作为“目标”
✅ VAE+Transformer:把图像映射到16维隐空间,再通过时序预测生成平滑、无抖动的电机指令
✅ 零样本跨语言:在11种语言上直接部署,无需微调,同步误差均落在英语基线范围内
✅ 量化评估:用隐空间距离替代主观打分,对比5种基线方法,证实学习框架的有效性
02 研究内容
🧩 硬件设计:为什么10个自由度是“刚需”
大多数仿人机器人的嘴唇只有开合能力,原因很简单:自由度越多,机械结构越复杂,控制难度呈指数上升。但这篇论文的团队偏偏“逆天”做了10个自由度。
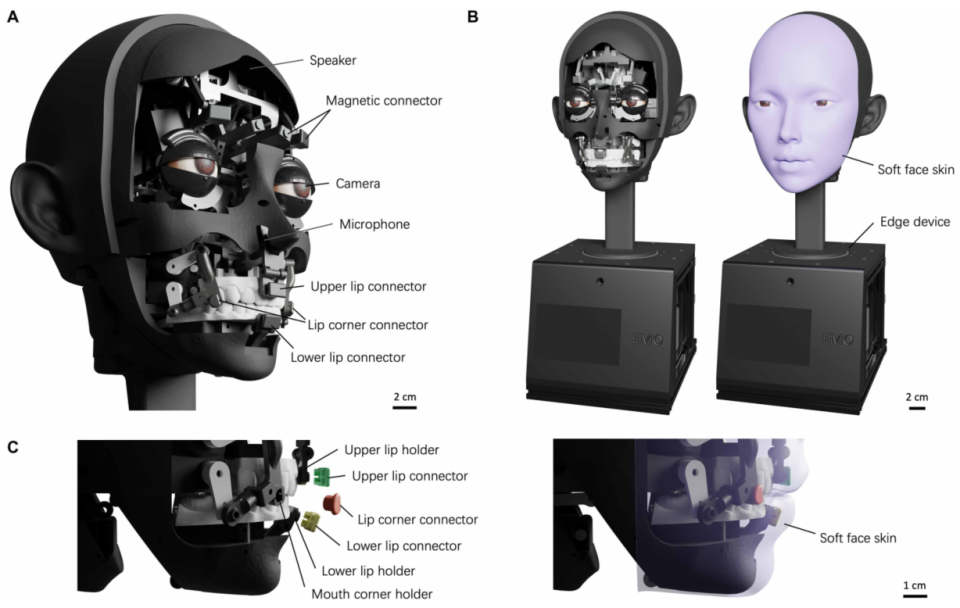
图1 机器人头部设计具有先进的机械关节。(A)面部机器人设计概述,强调人机交互的关键组件,包括扬声器、麦克风、高分辨率摄像头模块和固定柔软硅胶面部皮肤的磁性快速释放连接器。连接器允许精确对准,并允许皮肤的推拉运动,便于对语音清晰度至关重要的复杂嘴唇运动。(B)具有柔软硅树脂皮肤的人形机器人的外观。边缘计算设备容纳在基座中。(C)嘴唇驱动系统的详细视图,显示了上部、下部和角部嘴唇连接器,每个都连接到相应的嘴唇固定器上。柔软、可更换的面部皮肤使用磁性连接器固定,并且可以很容易地拆卸下来进行维护或定制。
为什么是10个?因为人类发“p/b/m”时需要上下唇完全闭合,发“f/v”时下唇需接触上齿,发“w/r”时嘴唇要噘起并前突。传统的2~4自由度机构根本做不到这些。他们的设计里,嘴角由两组叠放的电机驱动,能实现后拉+前突的二维运动;上唇和下唇独立升降,且连接件在运动时会自然外翻,模拟了人类嘴唇的“噘”动作。软硅胶皮肤通过磁吸快拆接头固定在机械结构上,方便迭代。

图2 面部机器人的嘴唇发音动作和相应的语音符号。该机器人展示了其重现关键英语音标的能力,如爆破音(/p/和/b/)、双音节音(/m/)和圆元音(/u/和/o/)。每一帧捕捉通过独立控制上嘴唇、下嘴唇和上嘴唇而实现的典型嘴唇运动。这些结果是机器人说话时产生正确嘴唇排列能力的基础。
🧠 自监督学习框架:从“预设动作”到“自主学会”
传统方法需要人工为每个音素设计唇形轨迹,耗时且僵化。他们的思路是:让机器人自己学。
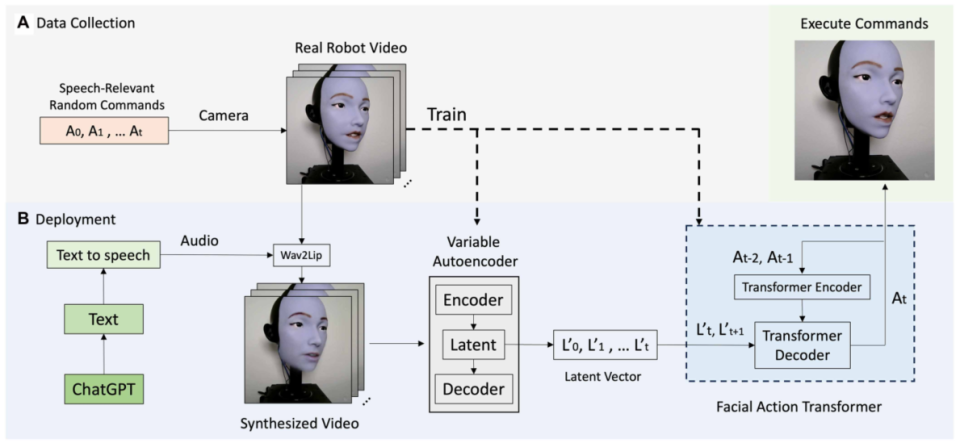
图3 机器人唇同步的自监督学习框架。(A)数据收集阶段涉及机器人通过与语音相关的随机命令自动生成数据集,用侧视图相机捕捉各种嘴唇运动以获得3D嘴唇形状数据。(B)部署过程从来自ChatGPT的文本输入开始,这些文本输入被转换成音频,然后合成机器人视频。真实机器人视频和命令用于训练由编码器和解码器组成的机器人逆变换器,以产生用于真实机器人执行的平滑和准确的电机命令。
数据采集阶段(图3A):机器人做各种随机面部运动,前置摄像头记录每帧画面,同时记录对应的10个电机指令。这是完全自监督的,没有任何人工标注。
部署阶段(图3B):给定一段文本,先用TTS转成音频,再用Wav2Lip生成一个与音频同步的“理想唇动”合成视频。然后用VAE把合成视频的每一帧映射到16维隐空间,这个隐空间是先用真实机器人图像预训练好的,所以合成图像的隐向量天然地与真实机器人的唇形状态对齐。最后用面部动作Transformer(FAT) 根据连续的隐向量和历史电机指令,预测出平滑的电机轨迹。
🎤 量化评估:比“幅度映射”好多少?
他们设计了一个严格的对比实验。用ChatGPT生成了3段测试文本,每段300~700帧。对比5种基线:最近邻(用Mediapipe提取唇部关键点做匹配)、幅度映射(仅根据音频幅度开合下颌)、0.033秒时移、0.5秒时移、随机选指令。
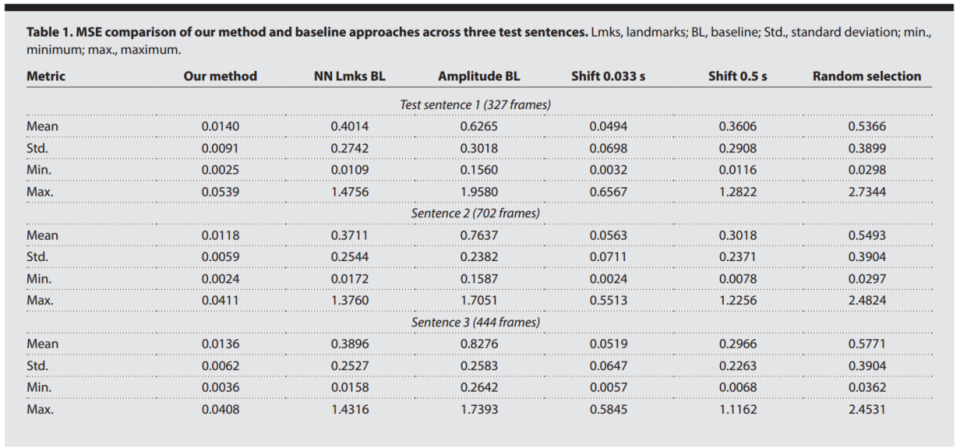
图4 我们的方法和基线方法在三个测试句子中的MSE比较。
图4显示,他们方法的MSE在0.0118~0.0140之间,比幅度映射(0.6265~0.8276)低两个数量级,也比最近邻(0.3711~0.4014)低一个数量级。有意思的是,0.033秒的时移就让MSE升到0.05左右,说明唇动同步对时间误差极其敏感。幅度映射居然比随机选还差,因为随机选的指令虽然不匹配音频,但至少是从“唇形分布”里采样的,幅度映射只能控制下颌一个自由度,反而破坏了自然感。
🌐 跨语言泛化:英语训练,11种语言测试
这是我觉得最惊艳的部分。训练数据只用了英语(20,000帧真实视频 + 5,173帧合成视频),但测试时直接输入法语、日语、俄语、阿拉伯语等11种语言的音频,不重新训练。
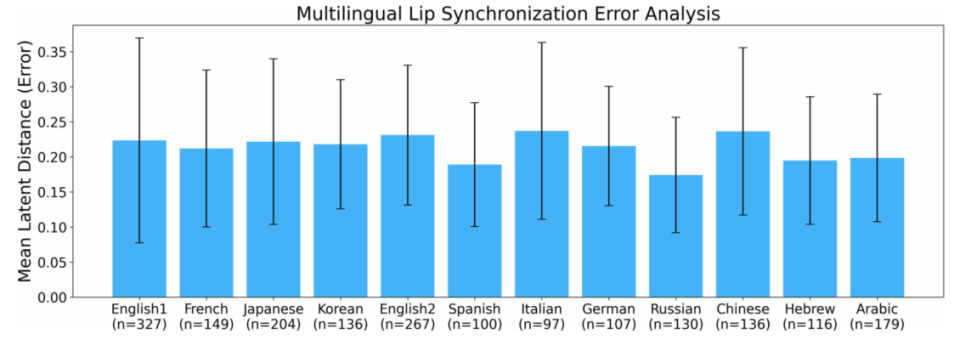
图5 多语言唇同步性能。每种语言的平均潜在距离误差用误差条表示SD。每种语言的样本大小n(显示在x轴标签下方)反映了该语言的测试句子中的视频帧数。结果表明,所有非英语语言的同步误差都保持在英语1的范围内,这表明跨语言泛化能力很强。
图5显示,所有非英语语言的MSE都落在英语基线的误差范围内。俄语、中文的误差稍高,但仍然在合理区间。更有意思的是,用同一个英语训练模型,对不同语音风格的英语(如老年男声)也能保持相近性能。这说明VAE学到的隐空间确实捕捉了“唇形”的核心特征,而不是过度拟合英语的音素分布。
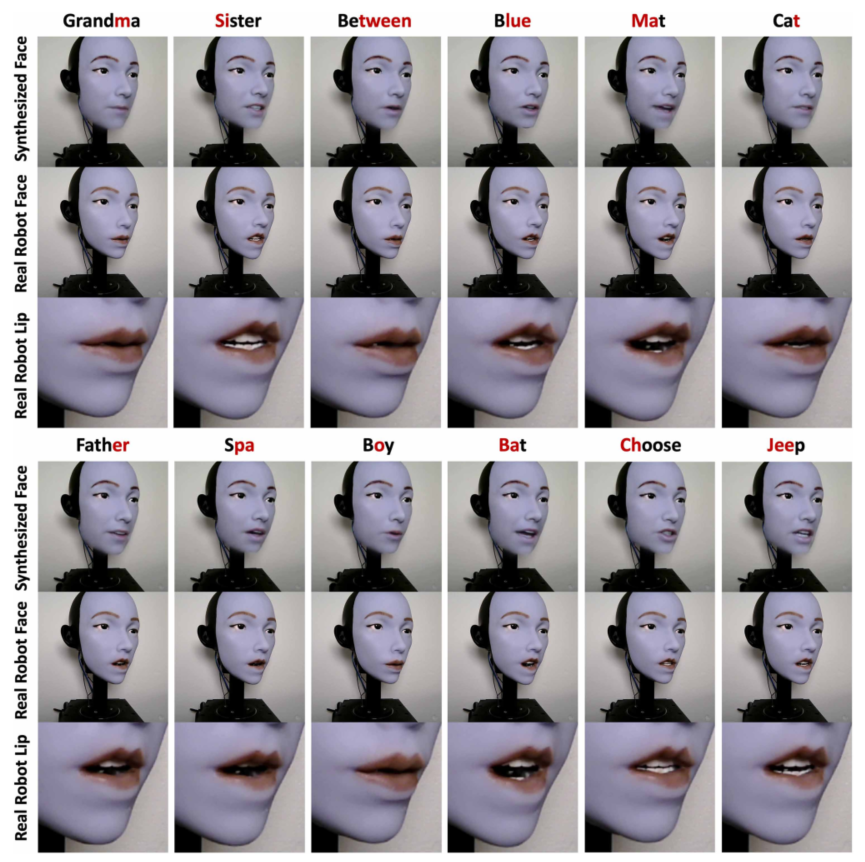
图6 不同语音环境下的机器人嘴唇运动。该图展示了机器人对各种单词的嘴唇形状的综合预测以及真实世界的机器人性能,说明了学习模型如何从模拟推广到物理执行。
03 创新点① 把“机械复杂度”和“学习框架”解耦
很多仿人机器人要么硬件简单、依赖复杂控制算法弥补;要么硬件复杂、控制逻辑完全人工设计。这篇论文做了一个很干净的拆分:硬件负责提供足够的运动学能力(10自由度),学习框架负责把“理想唇形”映射到可行的电机轨迹。这样,硬件的设计目标很明确(覆盖主要音素的唇形),学习的任务边界也很清晰(从图像到指令的平滑映射),两者不会相互干扰。
② 隐空间对齐:用VAE解决“仿真到现实”问题
Wav2Lip生成的合成视频在像素层面与真实机器人图像差异很大,直接拿来用会失效。他们的做法是:先用真实机器人图像预训练一个VAE,然后用这个VAE的编码器去处理合成视频,把合成图像“投影”到真实图像构成的隐空间。这本质上是一种无监督的域适配,不需要成对的合成-真实数据。
③ 时序建模:FAT平滑电机轨迹
如果逐帧独立预测电机指令,相邻帧之间会抖动。他们用一个Transformer编码器处理历史电机指令,再结合当前帧和未来两帧的隐向量,用解码器预测当前帧的电机指令。这样模型能看到“上下文”,生成的轨迹自然平滑。此外还专门设计了闭合损失,惩罚发“b/p/m”时唇部没有完全闭合的情况——因为人眼对这种错误特别敏感。
④ 定量化的唇动评估
传统方法要么靠主观打分,要么用像素级指标(如PSNR、SSIM)。但像素级指标不适合机器人,因为同样的电机指令在不同光照、角度下呈现的像素差异可能很大。他们改用隐空间距离:计算真实机器人图像和合成图像在VAE隐空间中的欧氏距离。这个指标既反映了语义层面的唇形相似性,又对视觉细节不敏感,很适合评价电机指令的准确性。
04 总结与展望读完这篇论文,我的第一感受是:仿人机器人的“表达力”可能真的到了一个拐点。
过去,我们关注的是“能不能动”“能不能说话”。但现在,讨论的是“动得自不自然”“说话时口型对不对”。这篇论文的意义,就是把后者从一个“人工调参”问题变成了“数据驱动”问题。硬件上做足自由度,软件上让模型自己去学,中间用隐空间对齐来桥接仿真和现实——这个技术栈一旦成熟,以后可能任何一个人形机器人拿到手,只要让它自己做几天“运动咿呀学语”,就能学会自然唇动。
当然,这离“完美”还有距离。他们的机器人目前只有嘴唇和下颌能动,脸颊、眉头等部位还没纳入。而且人类说话时,嘴唇的预运动(在声音发出前80~300毫秒就开始动作)还没被建模。但方向是对的:用更多的自由度、更多的数据、更好的时序模型,去逼近人的表达。
从控制的角度看,这项工作也提示了一种新思路:对于强非线性、高自由度的柔体系统,与其费劲建模和设计显式控制器,不如让系统先“探索”自己的运动空间,再通过学习从“目标状态”反推“控制指令”。这对我们做非线性控制的,也是一种提醒——有时候,设计一个好的“学习问题”,比设计一个好的控制器更有效。
未来研究将聚焦于以下几个方向:
🔸增加表情区域:目前的10个自由度都在唇部及下颌,未来可以扩展到脸颊、眉头、眼周,让机器人在说话时能有更丰富的表情配合,比如发元音时脸颊微涨。
🔸预运动建模:人类说话时,嘴唇在声音发出前就开始准备。如果能用带时间对齐的音频-视频-电机数据训练一个预测模块,可以进一步减少残余的时延。
🔸情感与语气的适配:同样的文本,用开心、严肃、犹豫的语气说出来,唇动幅度和节奏会不同。未来可以引入情感标签或语调特征,让唇动更有“表现力”。
🔸实时交互闭环:目前的流程是“文本→音频→唇动”,是开环的。如果能加入视觉反馈(比如通过眼球相机观察听者的反应),再实时微调唇动节奏,交互会更自然。
🔸伦理风险防范:论文最后专门提到了风险——当机器人能更自然地与人建立情感连接时,可能会被滥用,特别是对儿童和老年人。这是一个真实存在的伦理问题,需要设计者提前考虑。
如果让你给一个只有“开合”能力的仿人机器人增加唇动功能,你会选择先增加自由度,还是先改进控制算法?欢迎在评论区聊聊你的想法。
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。