英文题目:Surgical embodied intelligence for generalized task autonomy in laparoscopic robot-assisted surgery
中文题目: 用于腹腔镜机器人辅助手术中通用任务自主性的手术具身智能
作者:Yonghao Long, Anran Lin, Derek Hang Chun Kwok, Lin Zhang, Zhenya Yang, Kejian Shi, Lei Song, Jiawei Fu, Hongbin Lin, Wang Wei, Kai Chen, Xiangyu Chu, Yang Hu, Hon Chi Yip, Philip Wai Yan Chiu, Peter Kazanzides, Russell H. Taylor, Yunhui Liu, Zihan Chen, Zerui Wang, Samuel Kwok Wai Au, Qi Dou(通讯)
作者单位: 香港中文大学、约翰霍普金斯大学、康奈尔大学、Cornerstone Robotics
期刊:Science Robotics(IF 27.5 中科院一区,JCR一区)
发表时间:2025年7月16日
链接:https://www.science.org/doi/10.1126/scirobotics.adt3093
引文格式:Long Y, Lin A, Kwok D H C, et al. Surgical embodied intelligence for generalized task autonomy in laparoscopic robot-assisted surgery[J]. Science Robotics, 2025, 10: eadt3093.
01 全文速览
手术机器人已经完成了数百万例微创手术,但目前的机器人本质上还是医生的“遥控工具”。让机器人自主完成手术操作,是下一个技术高地——但要实现这一点,面临一个根本难题:手术场景太复杂,传统编程方法无法穷举所有情况。
香港中文大学领衔的团队给出了一套完整的解决方案,他们把它叫做手术具身智能。核心思路是在模拟环境中训练AI,然后把学到的技能直接部署到真实机器人上,不需要任何微调——这就是“零样本模拟到现实迁移”。
他们开源了一个专门的手术机器人学习模拟器SurRoL,并在此基础上开发了名为VPPV的四层学习框架:视觉解析(Visual parsing)用视觉基础模型理解手术场景;感知回归器(Perceptual regressor)把图像信息映射成物理状态;策略学习(Policy learning)用强化学习规划轨迹;视觉伺服(Visual servoing)用传统控制器完成最后一步精细操作。
实验结果很有说服力:在达芬奇研究套件上完成了7个基础技能训练任务,在商业化手术机器人上完成了5个手术辅助任务(镜头操控、持针、取纱布、组织牵拉、血管夹闭),全部实现零样本迁移。更关键的是,在活体猪的体内实验中,这些算法能在呼吸运动、组织变形、血污干扰等真实条件下稳定工作。
核心亮点:
✅零样本迁移:模拟器训练的策略直接部署到真实机器人,无需微调
✅统一框架:VPPV框架适用于7种技能训练和5种手术辅助任务,无需针对任务重新设计
✅视觉基础模型:用SAM和深度估计网络实现场景理解,对光照、烟雾、血污鲁棒
✅软体仿真:基于物质点法实现实时软组织变形模拟,支持组织牵拉任务训练
✅实体验证:达芬奇研究套件、商业化手术系统、离体组织、活体猪四个层面验证
02 研究内容🏥问题:手术机器人为什么难自主?
手术机器人要自主完成操作,面临两个核心挑战:一是场景太复杂(器械种类多、组织变形、血污遮挡),传统方法无法穷举所有情况;二是模拟到现实的鸿沟——模拟器里的图像和真实内窥镜图像差异太大,训练好的模型到真实环境中往往失效。
🧩解决方案:VPPV四层架构
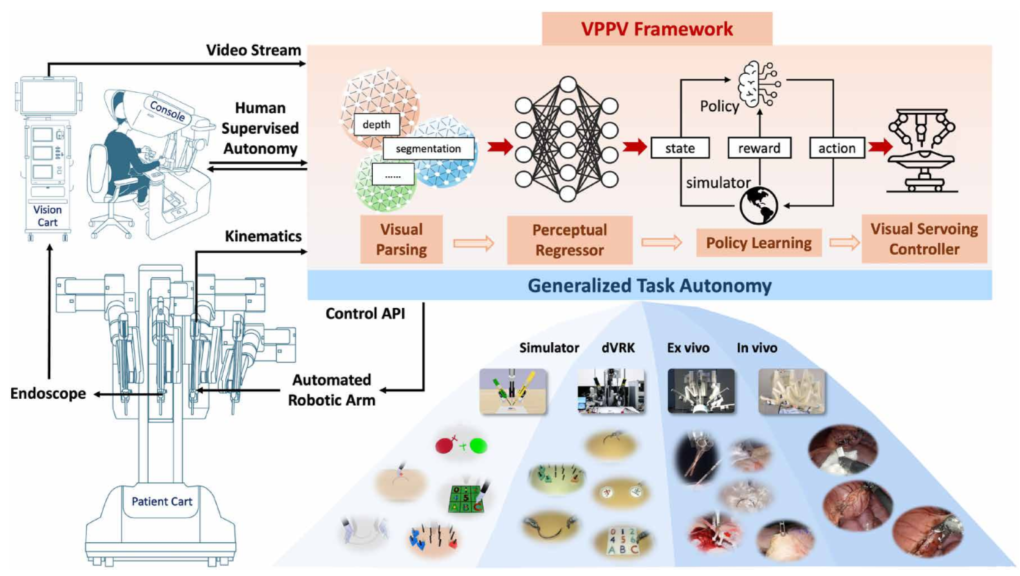
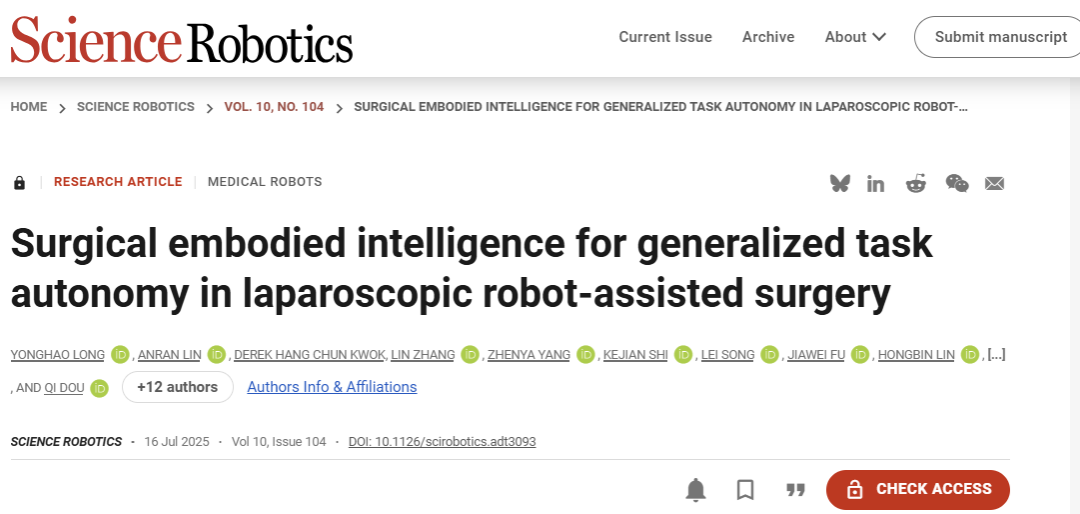
Figure 1:概念总览图。通过具体智能训练的基于视觉的学习范式可以实现手术机器人的通用任务自动化。
图1展示了整个VPPV框架。他们把这四个模块串联起来:视觉解析 → 感知回归 → 策略学习 → 视觉伺服。
第一层:视觉解析(Visual parsing)
这一步的目标是把内窥镜图像转换成机器人能理解的信息。他们用了两个视觉基础模型:
FastSAM:图像分割,用点提示的方式让模型找到目标物体(针、纱布、血管等)
IGeV:立体深度估计,从双目图像中算出物体在3D空间中的位置
这两个模型都是预训练好的,对光照变化、烟雾、血污有较好的鲁棒性。
第二层:感知回归器(Perceptual regressor)
这是实现零样本迁移的关键。传统方法直接把图像像素输入神经网络,但模拟器和真实图像有差异,模型学到的特征会失效。他们换了个思路:不直接学图像,而是学“图像+分割图+深度图”到“物理状态”的映射。
他们把分割图和深度图输入一个ResNet-18,输出一个9维的状态向量,包含:目标物体的3D位置、3D姿态、器械末端到目标的相对位置。这个回归器在模拟器中用12000对合成数据训练,模拟时加入了随机噪声(深度图加0-3mm的高斯噪声,分割图有30%概率随机丢失像素),保证模型对感知误差的鲁棒性。
第三层:策略学习(Policy learning)
基于回归器输出的状态,用深度确定性策略梯度(DDPG)训练策略网络。奖励函数是稀疏的:成功给0分,失败给-1分。这样可以鼓励机器人关注任务目标,而不是那些不重要的中间步骤。
训练时,状态包含:PSM机械臂的位姿、回归的环境状态、内窥镜图像中的3D目标点。
第四层:视觉伺服(Visual servoing)
策略网络负责把器械送到目标附近,最后一步精细操作交给传统的视觉伺服控制器。这样做的好处是:最后一步的精度要求高,传统控制器比学习型方法更可靠。
控制律很简单:把目标点从相机坐标系转换到PSM基坐标系,计算末端当前点到目标点的误差,驱动机械臂运动。
🧬软体仿真:让机器人学会“手感”
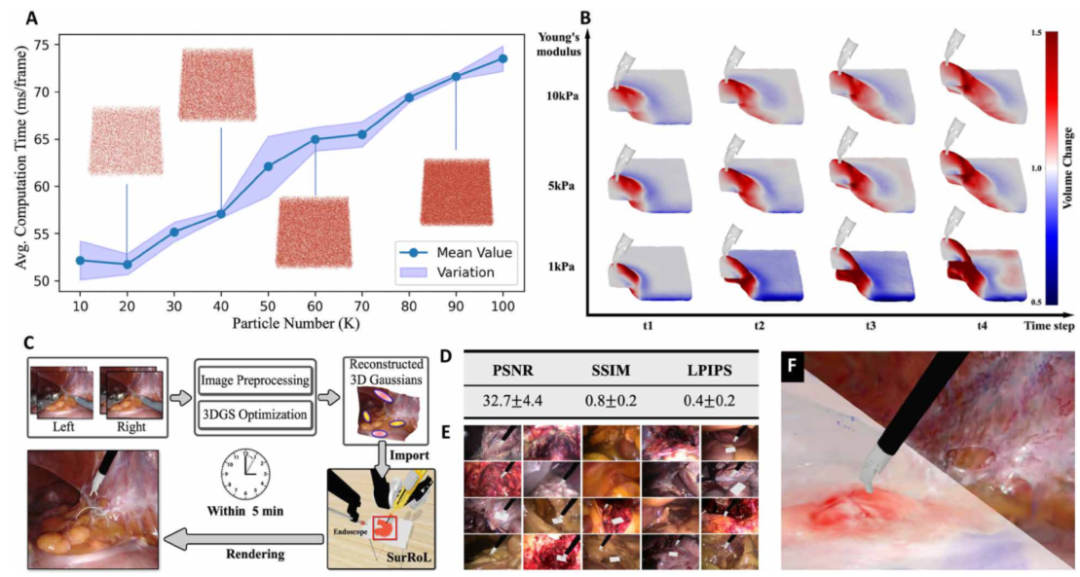
Figure 2:软组织仿真和数据驱动场景重建图。 (A) 随着粒子数量的增加,MPM 软体模拟的计算时间。(B) 具有不同杨氏模量的模拟软组织的变形场。 (C) 通过将 3D 重建结果导入 SurRoL 进行数据驱动的手术场景模拟。(D) 对 PSNR、SSIM 和 LPIPS 指标的重建结果进行定量评估,报告为平均值±SD。 (E) 可以从数据生成的各种场景的可视化。 (F) 生成的场景支持工具与组织的相互作用,并通过 SurRoL 中的 MPM 计算变形。
图2展示了软体仿真的技术细节。他们用物质点法(MPM)模拟软组织变形——把组织离散成粒子,每个粒子有位置、速度、密度、杨氏模量、泊松比等属性。工具与组织接触时,从接触点开始传播变形场。图2B显示了不同杨氏模量(1、5、10 kPa)下的变形差异,刚度越小,变形越大。
为了提升场景真实感,他们用3D高斯泼溅(3DGS)从真实手术视频中重建场景,生成的虚拟场景可以导入SurRoL,支持工具与组织的交互仿真(图2F)。
🧪实验验证:四层递进
Figure 3:模拟器中不同策略学习方法的基准测试以及与我们在现实世界机器人上的方法的比较。 CoL,学习周期; AWAC,优势加权演员评论家; IQL,隐式Q学习; BeT,行为转换器; DEX,示范引导探索; RLPD,利用先验数据进行强化学习; RLIF,通过干预反馈强化学习; GCDT,目标条件决策变压器。
图3的表格对比了十几种RL/IL方法。他们的VPPV方法在模拟器中的成功率高得离谱:NeedleReach、NeedlePick、GauzeRetrieve三个简单任务都是100%,PickAndPlace 90%,PegTransfer 98%,MatchBoard 83%,NeedleRegrasp 96%。更关键的是,把这些策略直接部署到达芬奇研究套件上,成功率只下降了8%左右——这就是零样本迁移的效果。作为对比,ALOHA和Diffusion Policy在模拟器里能学,一到真实世界就失效。
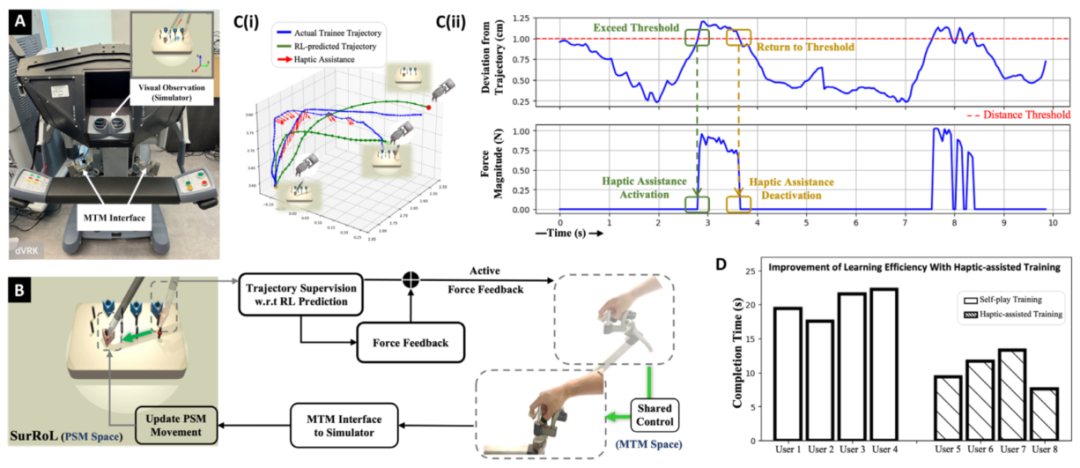
Figure 4:SurRoL 人机界面的图示和结果及其在触觉辅助技能教育中的应用。 (A) 模拟器连接到 dVRK 的 MTM。 (B) 我们提出的触觉辅助手术技能训练方法,该方法使用强化学习预测轨迹通过人机共享控制提供智能指导。 (C) (i) 仪器运动轨迹的可视化(钉转移任务),其中在检测到相对较大的偏差时激活触觉辅助。 (ii) 轨迹偏差和力大小随时间的可视化。 (D) 通过测量训练后任务完成时间来提高学习效率的用户研究。
图4展示了SurRoL的人机交互功能。他们用达芬奇的主手(MTM)直接控制模拟器中的虚拟机械臂,实现了双向力觉反馈。基于这个功能,他们做了一个力觉辅助训练的实验:RL预测的轨迹作为“正确路径”,新手偏离路径时,主手会施加一个力把他们“拉”回来。图3D显示,经过15分钟训练,有力觉辅助的新手完成任务只需10.5秒,而自学的要20.2秒——提升了近一倍。
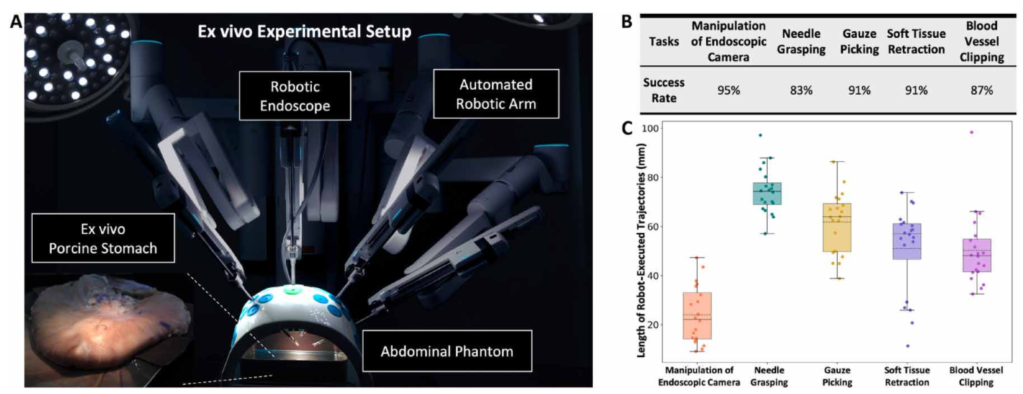
Figure 5:使用 Sentire 手术系统对五种手术辅助任务进行离体验证。 (A) 使用离体猪组织的实验装置的图示。(B) 五次进行的手术辅助任务的成功率。 (C) 从运动学数据记录的每个任务的机器人执行轨迹长度的结果。
图5是离体实验的统计结果。他们用商业化手术系统Sentire,在猪胃组织上测试了五个任务:
镜头操控(成功率95%):自动调整内窥镜位姿,把器械保持在视野中央
持针(83%):自主抓取放在组织表面的针,针的大小从15mm到35mm
取纱布(91%):自主抓取纱布并放到出血点
组织牵拉(91%):自主抓取并牵拉组织,为其他器械创造操作空间
血管夹闭(87%):自主把夹子放到血管上
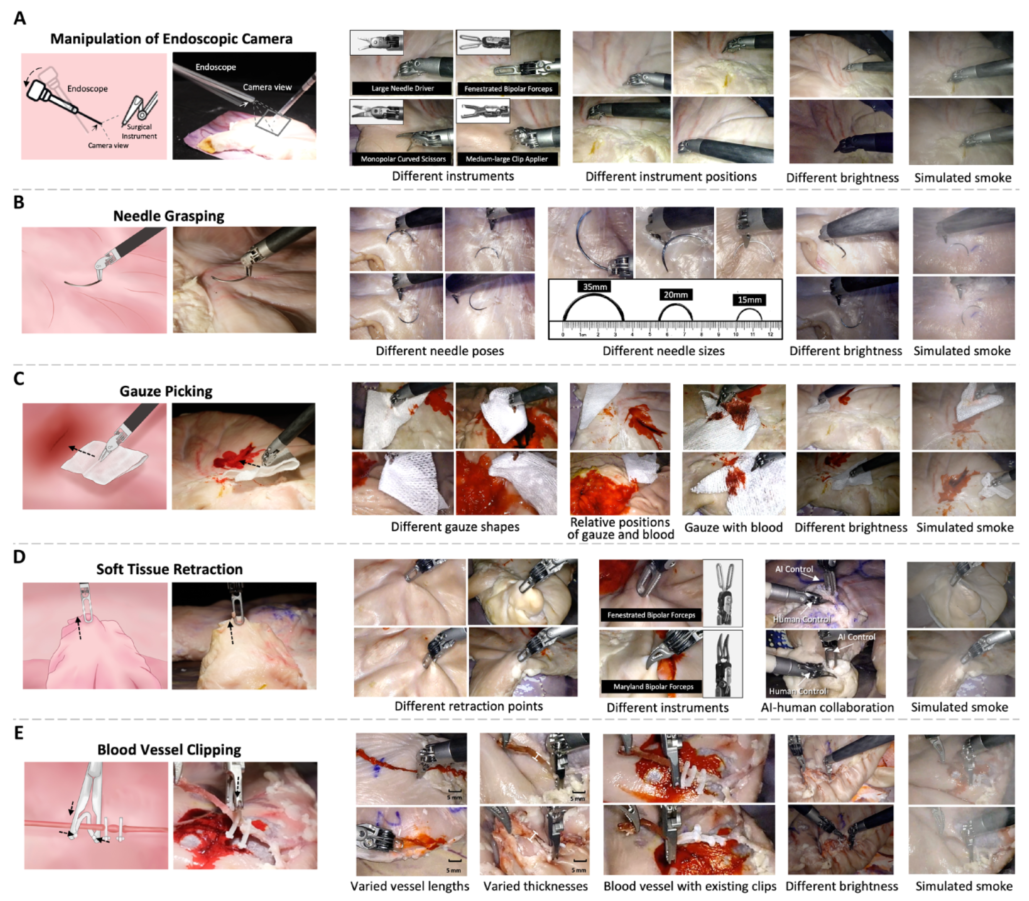
Figure 6:离体实验中五项任务的真实世界场景的不同设置。 (A) 内窥镜摄像机的操作。 (B) 抓针。 (C) 纱布挑选。(D) 软组织收缩。 (E) 血管夹闭。
图6展示了每种任务在真实环境中的挑战:不同器械类型、不同物体大小、不同照明、烟雾、血污。VPPV都能应对。
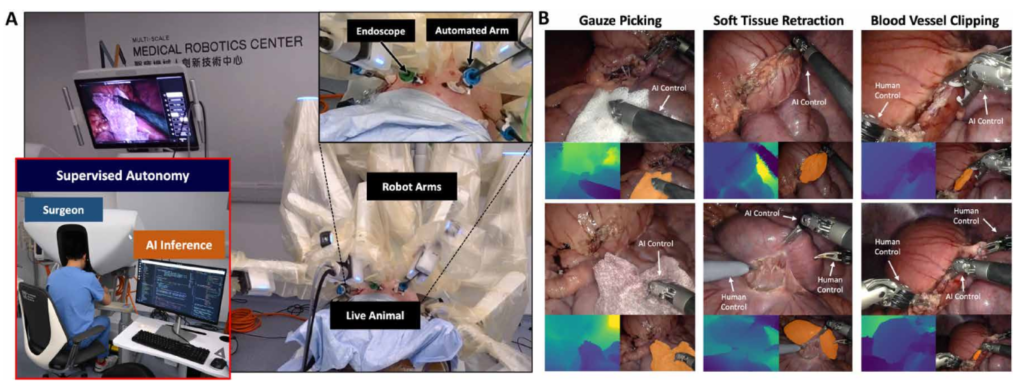
Figure 7:在自主监督下通过活体动物试验进行体内验证。 (A) 香港多尺度医疗机器人中心混合手术室的体内实验装置。 (B) 自动化手术任务的图示,包括纱布拾取、软组织牵开和血管夹闭。每个任务显示两个示例场景,其中包含内窥镜图像(上)、估计深度图(左下)和目标对象分割(右下)。
图7是最终的活体猪实验。在麻醉的猪体内,他们测试了取纱布、组织牵拉、血管夹闭三个任务。成功率分别是83%、77%、67%。失败的主要原因是:呼吸运动导致目标漂移、软组织变形导致抓取困难、血管太细对精度要求极高。但即使有这些挑战,算法仍然能完成大部分操作。
03 创新点
①零样本模拟到现实迁移
这是整篇论文最核心的贡献。他们没有像大多数研究那样在真实机器人上微调,而是通过设计可解释的中间表示(分割图+深度图→物理状态)来消除模拟与现实的视觉差异。只要视觉解析模块能在真实图像中稳定工作,后面的策略就能直接用。
②四层解耦架构
VPPV把“感知→规划→执行”拆成了四层,每层各司其职。视觉解析用基础模型,不依赖特定任务;感知回归器负责把图像变成物理状态;策略学习负责高层路径规划;视觉伺服负责低层精细控制。这种解耦的好处是每一层都可以独立升级,比如未来可以用更好的基础模型替换视觉解析模块。
③开源的完整基础设施
他们开源了SurRoL模拟器(https://github.com/med-air/SurRoL),包含了达芬奇机器人的数字孪生、软体仿真引擎、强化学习库,还有7个基础技能训练任务和5个手术辅助任务的资产。这对整个手术机器人社区非常有价值——研究者不需要从头搭建模拟环境,可以直接在这个平台上开发新算法。
④软体仿真的效率突破
用物质点法(MPM)模拟软组织变形,在单个GPU上能跑100帧以内,粒子数从1万到10万,计算时间小于100毫秒。这个速度对强化学习训练来说是可以接受的。他们还用3D高斯泼溅从真实手术视频重建场景,解决了手工建模不够真实的问题。
⑤全链条验证
从模拟器到达芬奇研究套件,从离体组织到活体猪,验证链条完整。特别是活体猪实验,呼吸运动、软组织变形、血污遮挡,这些都是模拟器很难复现的,算法仍然能完成大部分操作,说明设计是鲁棒的。
04 总结与展望这篇论文的意义在于:它证明了手术机器人可以通过模拟训练学会多种操作,并且这些技能可以直接用到真实环境中。VPPV框架的核心思想——用可解释的中间表示连接视觉和决策——可能是解决“模拟到现实”问题的一个通用方案。
从工程角度看,他们的设计思路很务实:不试图用端到端网络解决所有问题,而是把任务拆解成视觉、规划、执行三个层次,分别用最适合的方法处理。视觉用基础模型,规划用强化学习,执行用传统控制。这种“取其精华”的思路,值得在其他机器人任务中借鉴。
未来研究将聚焦于以下几个方向:
🔸更长序列任务:目前的任务都是一到两步操作,要真正实现手术自动化,需要让机器人学会多步骤任务的编排和执行。这可能需要用大语言模型或分层强化学习来实现技能的组合。
🔸更安全的强化学习:在真实手术中,强化学习的探索过程可能带来风险。需要研究安全的探索策略(如人机共享控制)或在模拟中完成所有探索。
🔸更快的推理速度:目前深度估计要300毫秒一帧,策略预测7毫秒,总帧率约3帧/秒。要提高响应速度,可能需要轻量化模型或硬件加速。
🔸更精确的感知:血管夹闭任务中,血管直径约5mm,夹子10mm,深度估计的误差可能导致夹偏。需要更高精度的3D重建方法。
🔸更智能的人机交互:目前是“监督自主”模式——人启动任务,AI执行。未来可以发展更紧密的人机协作,比如AI预测医生的意图、提前准备工具、或根据医生的动作调整自己的策略。
🔸扩展到其他手术机器人平台:目前验证了达芬奇和Sentire两个平台,理论上VPPV是平台无关的。需要更多平台上的验证来证明通用性。
你认为手术机器人应该追求完全的“自主”还是“协同”?在安全性和效率之间,如何权衡?欢迎在评论区分享你的观点。
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。